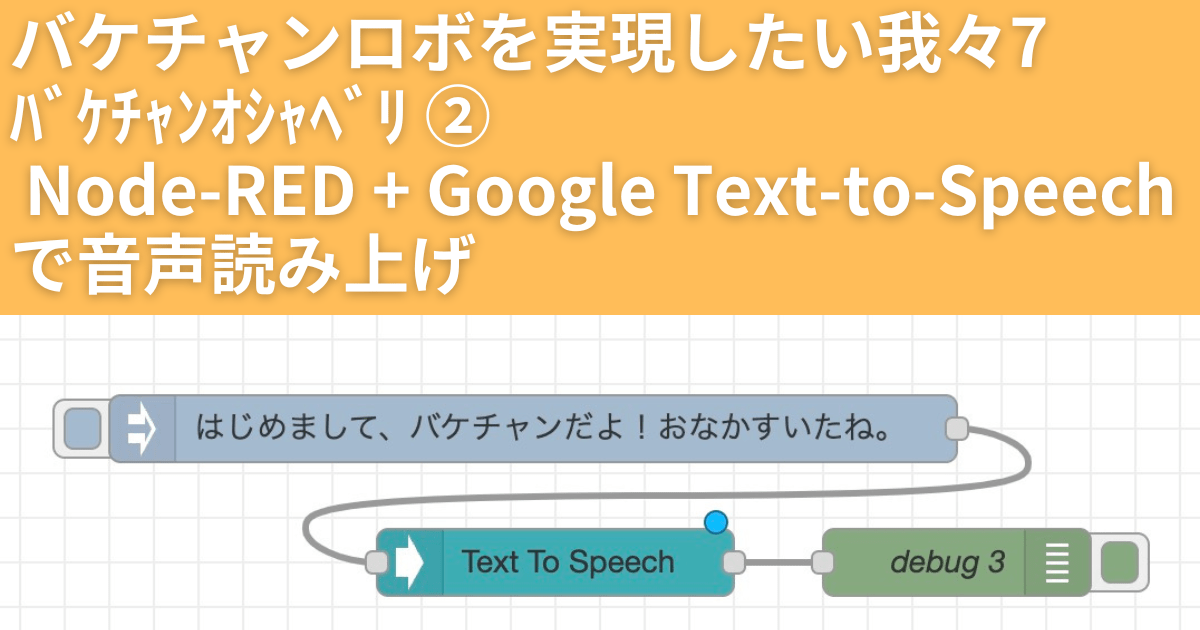
バケチャンロボを実現したい我々7 – バケチャンオシャベリ ② Node-RED + Google Text-to-Speechで音声読み上げ
本記事にはアフィリエイト広告が含まれます。
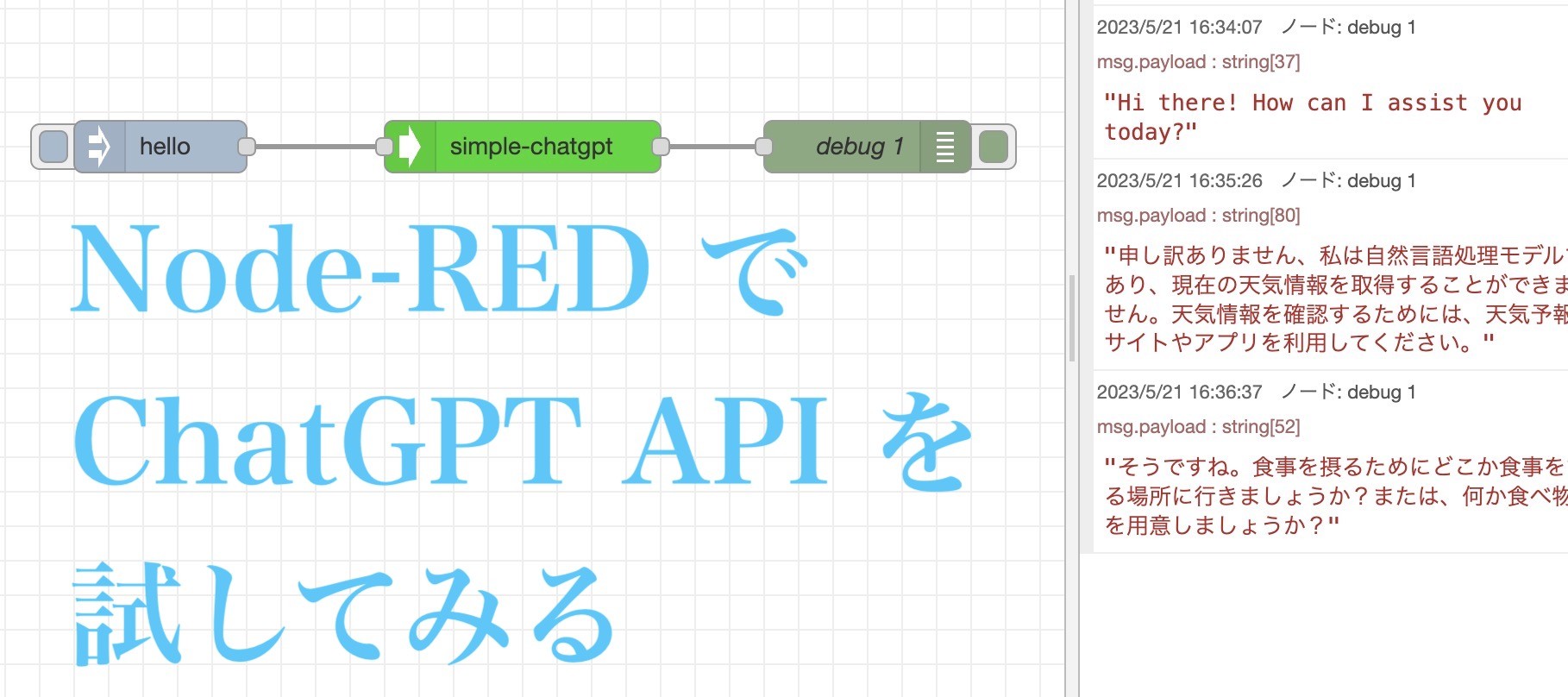
バケチャンオシャベリは Node-RED + ChatGPT で計画しており、
前回はOpenAI のAPIで音声認識が出来ました。
今回は Google Cloud Text-to-Speech API で
音声読み上げを試してみたいと思います。
目次
Google Cloud登録
Google Cloud の登録方法はこちらの記事にまとめました。
Google Cloud Text-to-Speech API
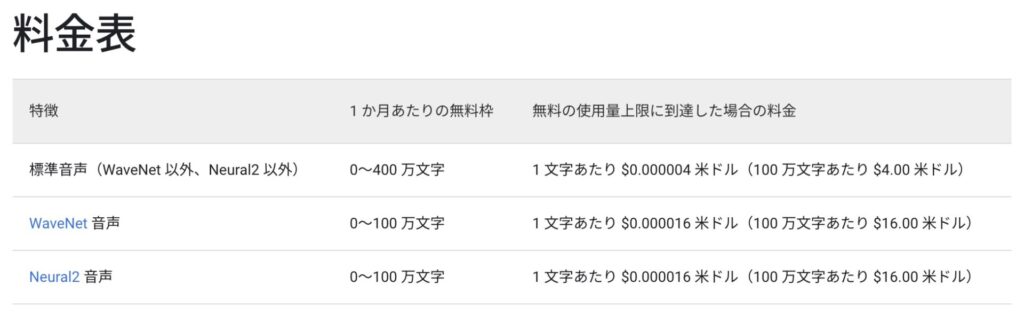
Text-to-Speech API 料金
料金 | Cloud Text-to-Speech | Google Cloud
料金については100万文字以下は無料のようなので
無料枠で充分そうです。
APIを使用する為の設定
こちらを参考にさせて頂きました 🙏
GCP Text-to-Speech APIの使い方~Pythonで音声出力 – Masa engineer blog
「1 .Cloud text-to-Speech APIサービスの有効化とAPIキーの取得」を行い、
Jsonファイルをダウンロードしておきます。(後で必要)
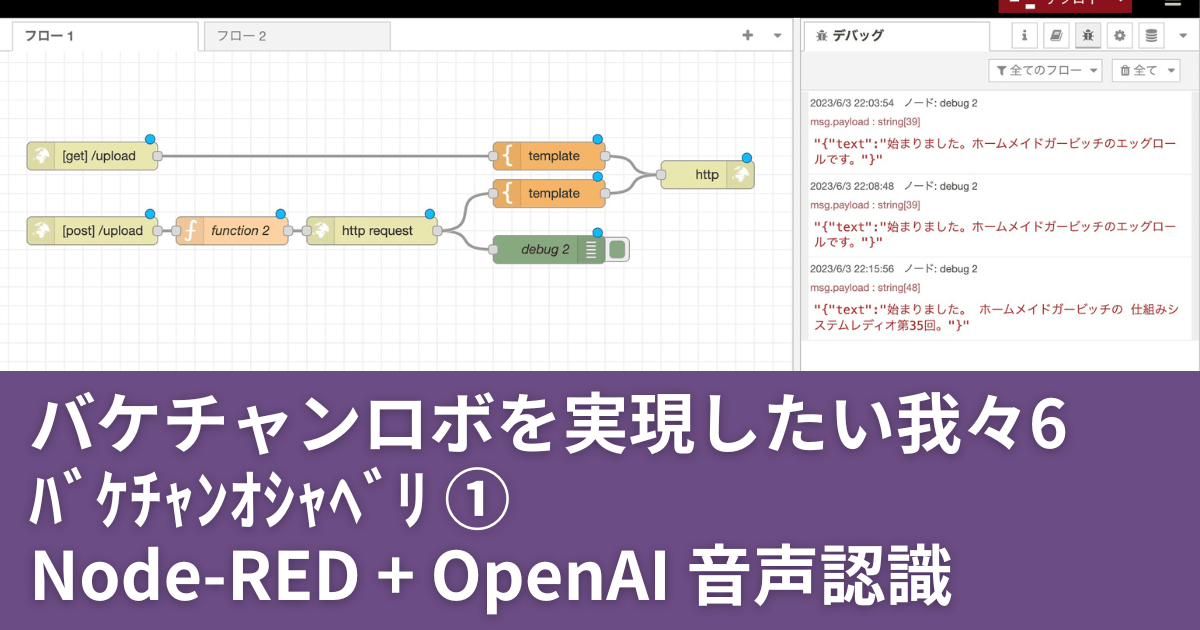
Node-RED
node-red-contrib-google-cloud-text-to-speech
パレットの管理から「node-red-contrib-google-cloud-text-to-speech」を検索して追加する
node-red-contrib-google-cloud-text-to-speech (node) – Node-RED

ノードの設定
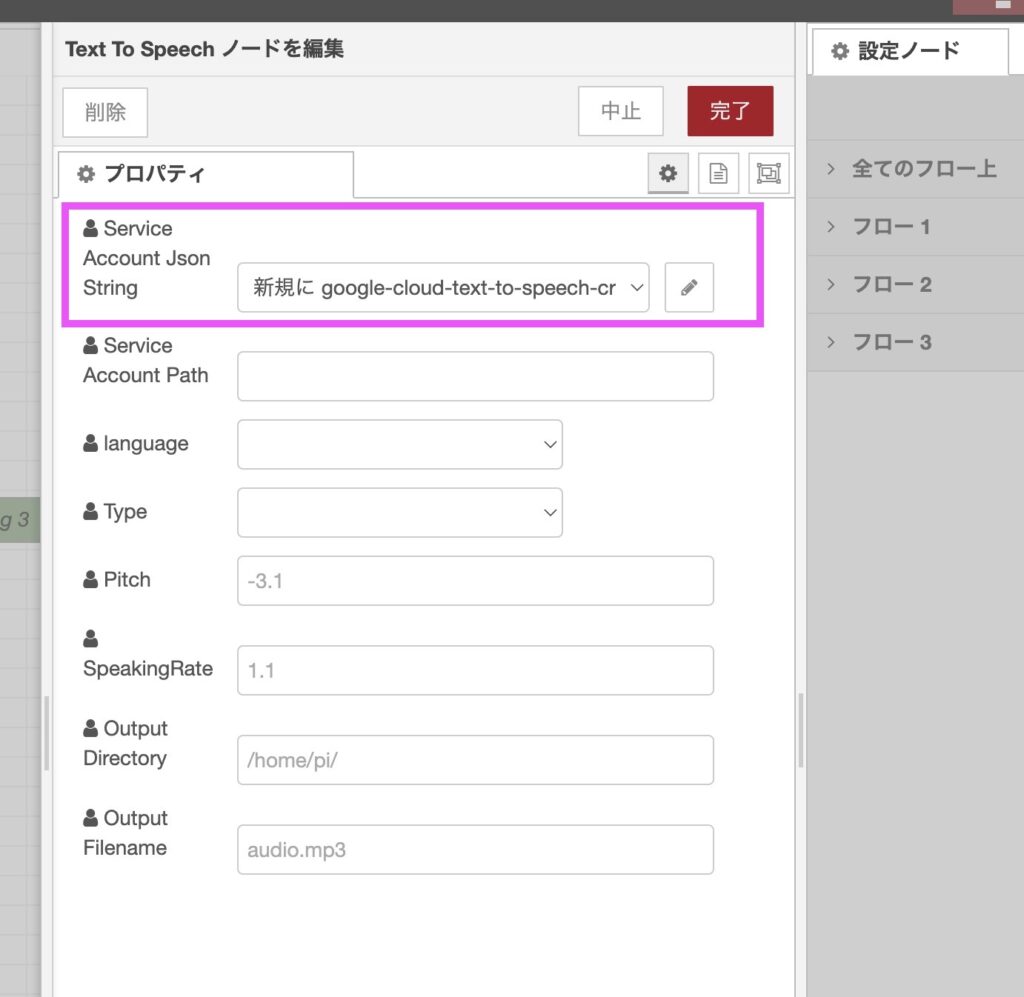
「Service Account Json String」の設定
Service Account Json String に、先程API設定で作成・ダウンロードしたJSONの内容を登録します。
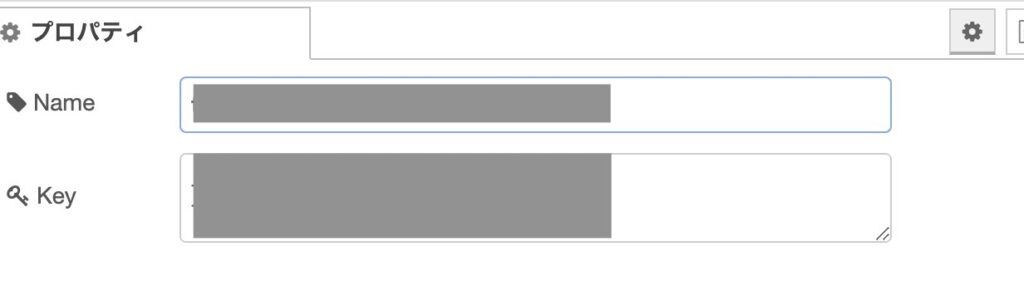
項目右側のペンのアイコンをクリックして下記を設定
Name:適当に
Key:ダウンロードしたJsonファイルの内容をコピペ
Service Account Path
その下の「Service Account Path」は何を設定するのかわかりませんでしたが、設定無しでも大丈夫でした。
その他項目設定
language、Type、Output Filename を設定します。
ファイル名は「audio.mp3」で出力されます。
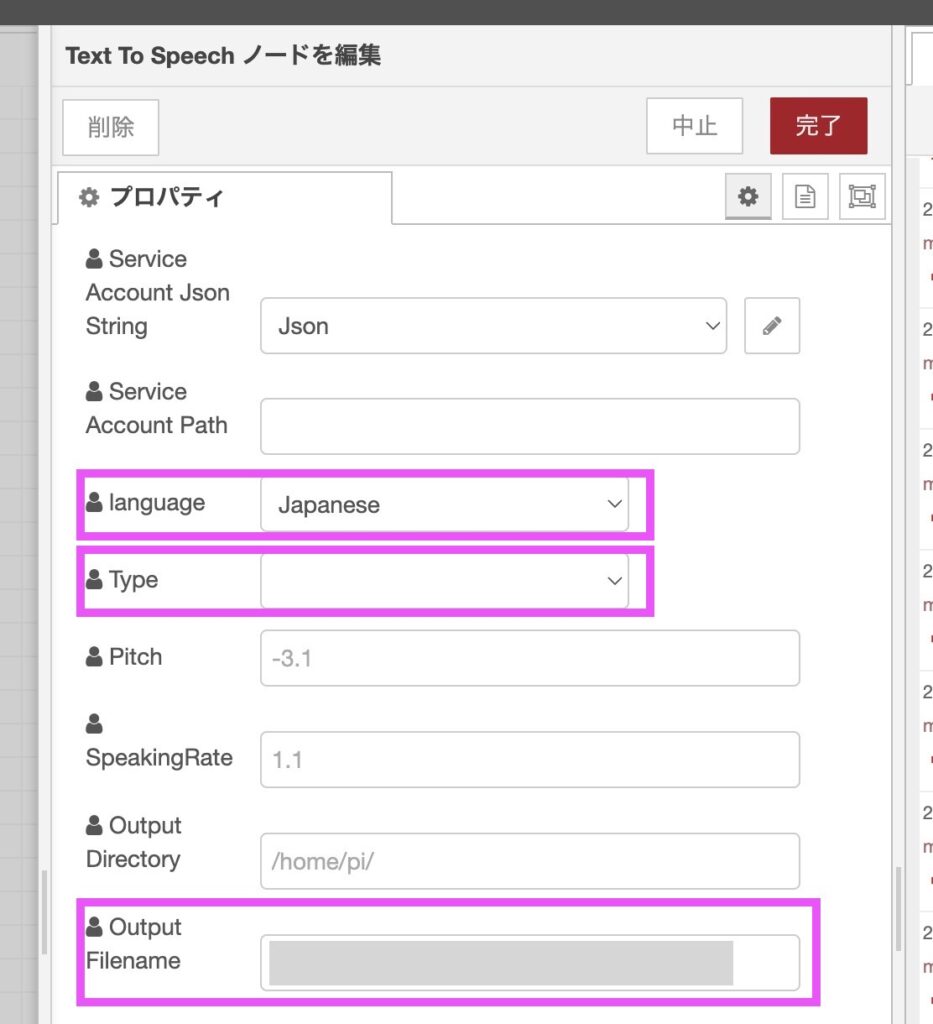
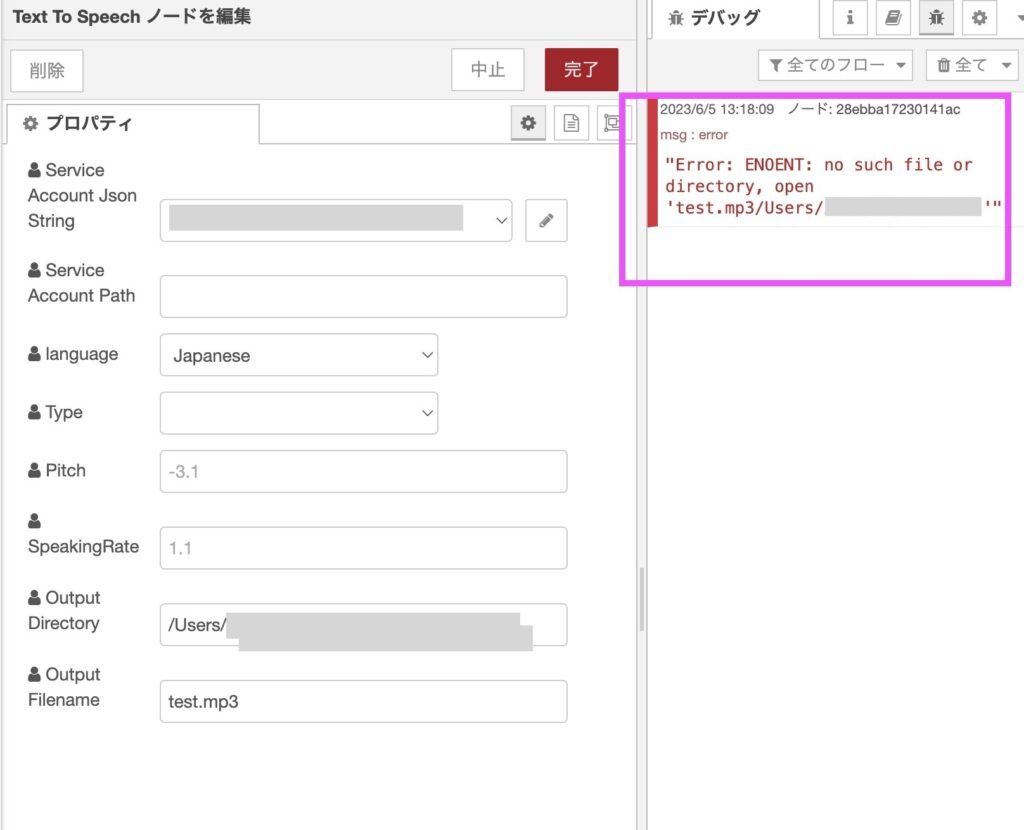
※ Output Filename について
Output Directory と Output Filename を両方設定したところ、
Filename + Directory の形で出力されてしまい、directoryが存在しないエラーが出てしまったので、
「Output Filename」の方に出力パスを設定しています。
フロー
inject ノード に 文字列を設定して、デプロイ> 実行
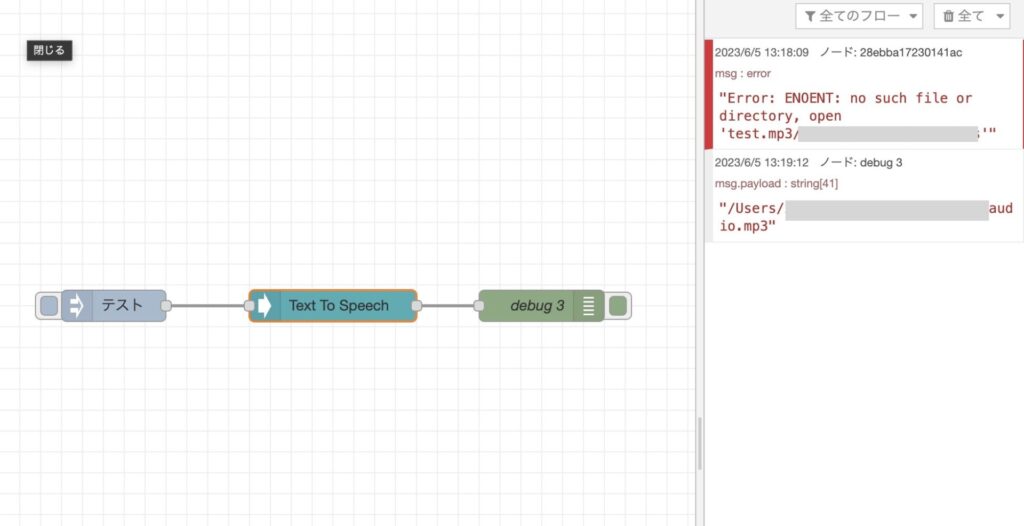
実行
実行すると、指定したディレクトリにmp3が生成されました!!🙌
声確認など
声タイプは4種類ありました。

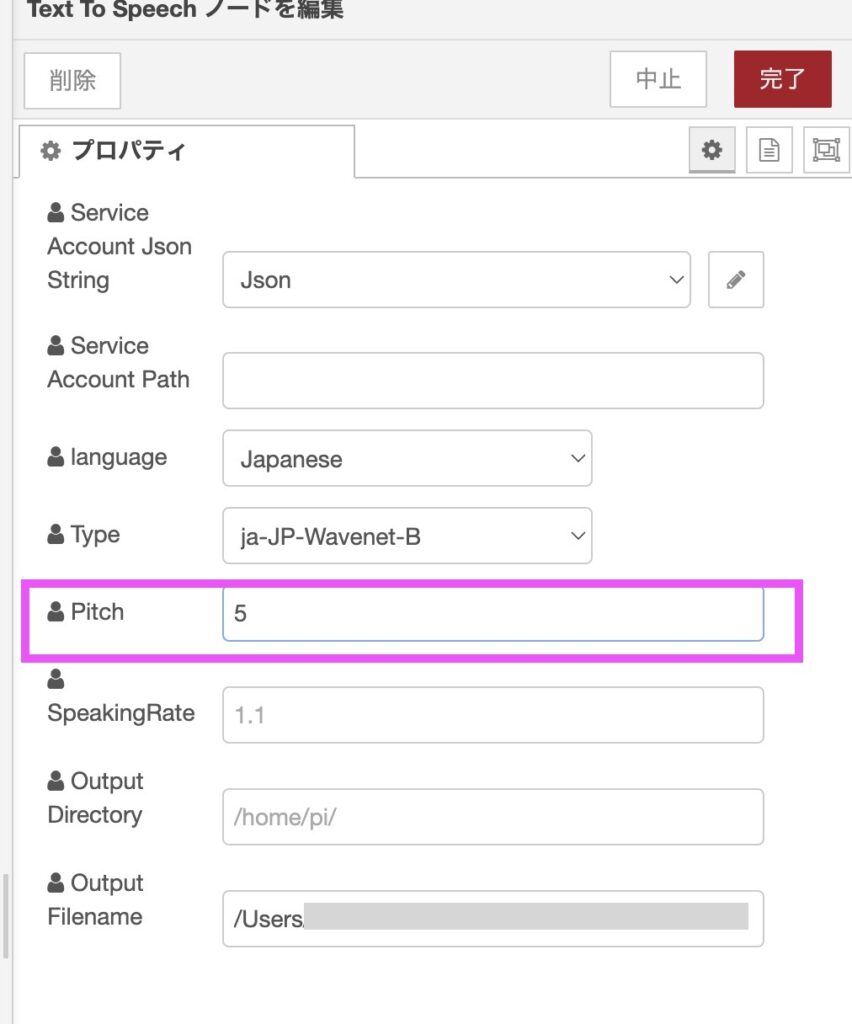
バケチャンの声としては、ちょっと子供っぽくしたいのでピッチを上げてみます。
上げすぎるとガサガサになるので5位が限界かなぁ…。
ja-JP-Wavenet-A
ja-JP-Wavenet-B
ja-JP-Wavenet-C
ja-JP-Wavenet-D
バケチャンは AかBかな〜 🤔👻
イントネーションも微妙に違っていて、
語尾の「だよ」や「ね」が、Aは下がってBは上がってる!