強化学習への道7 -ロボット強化学習3-
本記事にはアフィリエイト広告が含まれます。
前回はロボ関節をギアを含めたアクチュエータとしてモデリングして、角度指定による2足歩行ロボットモデルを完成させました。
ここではこのモデルでロボット動作の強化学習を実施たいと思います。
目次
バランス強化学習
中腰で立ってIMUで姿勢角を検知してバランスするよう強化学習します。
構成は毎度の MuJoCo + Gymnasium + Stable-Baselines3 で
入力 (observation)が
機体ロール・ピッチ角 [rad]
機体ロール・ピッチ角速度 [rad/s]
各関節角度 [rad/]
出力 (action)が
正規化された各関節角度
ロボット全体での強化学習の感覚つかむのにかなり時間かかったけど何とか中腰バランスできた。
学習は0.001でやってます。
ビューもそのままだったので遅くなってました。
間引いて表示に修正しました。#強化学習への道#ReinforcementLearning pic.twitter.com/0sb5gZzROh— HomeMadeGarbage (@H0meMadeGarbage) June 2, 2025
環境ファイルは以下の通り
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 |
import gymnasium as gym from gymnasium import spaces import numpy as np import mujoco from mujoco_model import get_model_xml import math class BipedalStandEnv(gym.Env): def _set_squat_pose(self): target_angles = np.radians([-50, 100, -50, 0, -50, 100, -50, 0]) angle_ids = [self.model.jnt_qposadr[i] for i in self.joint_ids] for i, qid in enumerate(angle_ids): self.data.qpos[qid] = target_angles[i] mujoco.mj_forward(self.model, self.data) def __init__(self, render_mode=None): self.model = mujoco.MjModel.from_xml_string(get_model_xml()) self.data = mujoco.MjData(self.model) self.render_mode = render_mode self.viewer = None self.dt = self.model.opt.timestep self.time = 0.0 self.np_random = np.random.default_rng() self.hip_site = mujoco.mj_name2id(self.model, mujoco.mjtObj.mjOBJ_SITE, "hip") self.footL_site = mujoco.mj_name2id(self.model, mujoco.mjtObj.mjOBJ_SITE, "footL") self.footR_site = mujoco.mj_name2id(self.model, mujoco.mjtObj.mjOBJ_SITE, "footR") self.hip_id = mujoco.mj_name2id(self.model, mujoco.mjtObj.mjOBJ_BODY, "hip") self.observation_space = spaces.Box( low=np.array( [-math.radians(80), -math.radians(80), -math.radians(250), -math.radians(250)] + [-math.radians(90)] * 8, dtype=np.float32 ), high=np.array( [math.radians(80), math.radians(80), math.radians(250), math.radians(250)] + [math.radians(90)] * 8, dtype=np.float32 ), dtype=np.float32 ) self.action_space = spaces.Box( low=np.full(8, -1.0, dtype=np.float32), high=np.full(8, 1.0, dtype=np.float32), dtype=np.float32 ) joint_names = [ "legL1_joint", "legL2_joint", "hipLpitch_joint", "hipLroll_joint", "legR1_joint", "legR2_joint", "hipRpitch_joint", "hipRroll_joint" ] self.joint_ids = [ mujoco.mj_name2id(self.model, mujoco.mjtObj.mjOBJ_JOINT, name) for name in joint_names ] self.angle_ids = np.array([self.model.jnt_qposadr[i] for i in self.joint_ids]) self._set_squat_pose() self.data.qpos[2] = -0.06 mujoco.mj_forward(self.model, self.data) def xmat_to_euler(self): # 回転行列(3x3)を取得(9要素 flat) xmat = self.data.xmat[self.hip_id] r00, r01, r02 = xmat[0], xmat[1], xmat[2] r10, r11, r12 = xmat[3], xmat[4], xmat[5] r20, r21, r22 = xmat[6], xmat[7], xmat[8] # Z-Y-X順(Y軸がroll、X軸がpitch) if abs(r20) < 1.0: roll = -math.asin(r20) # Y軸回転(左右)=ロール pitch = math.atan2(r21, r22) # X軸回転(前後)=ピッチ else: pitch = math.pi / 2 * np.sign(-r20) roll = 0 return pitch, roll def _get_obs(self): pitch, roll = self.xmat_to_euler() # x軸=ピッチ, y軸=ロール # base(hip)の角速度(qvel[3] = x軸回転、qvel[4] = y軸回転) pitch_vel = self.data.qvel[3] roll_vel = self.data.qvel[4] # 関節角度・速度(joint_ids ベース) gear_angles = self.data.qpos[self.angle_ids] # 観測値を1つのベクトルにまとめる obs = np.concatenate(( np.array([pitch, roll, pitch_vel, roll_vel], dtype=np.float32), gear_angles.astype(np.float32) )) return obs def step(self, action): # --- time更新 --- self.time += self.dt # [-1,1] → ctrlrangeに変換 # ctrlrange = self.model.actuator_ctrlrange[:8] # low, high = ctrlrange[:, 0], ctrlrange[:, 1] # self.data.ctrl[:8] = low + (action + 1.0) * 0.5 * (high - low) center = np.radians([-50, 100, -50, 0, -50, 100, -50, 0]) scale = np.radians([50, 50, 50, 5, 50, 50, 50, 5]) # ±スケーリング幅 self.data.ctrl[:8] = center + action * scale mujoco.mj_step(self.model, self.data) obs = self._get_obs() pitch, roll, pitch_vel, roll_vel = obs[:4] gear_angles = obs[4:12] # 報酬 reward = ( - pitch**2 - roll**2 - 0.01 * pitch_vel**2 - 0.01 * roll_vel**2 ) # しゃがみ角度との一致を報酬に(強力) target_angles = np.radians([-50, 100, -50, 0, -50, 100, -50, 0]) reward -= 5.0 * np.sum((gear_angles - target_angles) ** 2) # 静止安定化ボーナス if abs(pitch) < math.radians(1) and abs(roll) < math.radians(1): reward += 30.0 footL_pos = self.data.site_xpos[self.footL_site] footR_pos = self.data.site_xpos[self.footR_site] foot_dist = np.linalg.norm(footL_pos[:2] - footR_pos[:2]) # 2次元ユークリッド距離 # ペナルティ追加 #reward -= 5.0 * foot_dist hipZ = self.data.site_xpos[self.hip_site][2] # hipZの目標値との差に基づいた報酬 reward -= 3000.0 * (hipZ - 0.16)**2 # --- ログ --- print(f"[STEP] time={self.time:.3f}, pitch={np.degrees(pitch):>6.2f}, roll={np.degrees(roll):>6.2f}, foot_dist={foot_dist:.4f}, hipZ={hipZ:.4f}, reward={reward:6.3f}") #print(f"pitch={pitch:.2f}, roll={roll:.2f}, pitch_vel={pitch_vel:.2f}, roll_vel={roll_vel:.2f}, qpos[0:7]={self.data.qpos[0:7]}s") # 終了条件 転倒 terminated = ( abs(pitch) > math.radians(45.0) or abs(roll) > math.radians(45.0) ) truncated = False if self.time > 45.0: truncated = not terminated terminated = False # 転倒じゃない終了として扱う return obs, reward, terminated, truncated, {} def reset(self, seed=None, options=None): super().reset(seed=seed) mujoco.mj_resetData(self.model, self.data) self.time = 0.0 # ベース位置初期化 self.data.qpos[0:3] = np.array([0.0, 0.0, 0.0]) # x, y, z self.data.qvel[0:6] = 0.0 #姿勢:わずかにランダム傾ける pitch_offset = self.np_random.uniform(-math.radians(10), math.radians(10)) roll_offset = self.np_random.uniform(-math.radians(3), math.radians(3)) quat = np.zeros(4, dtype=np.float64) euler = np.array([pitch_offset, roll_offset, 0.0], dtype=np.float64) mujoco.mju_euler2Quat(quat, euler, "xyz") self.data.qpos[3:7] = quat # --- しゃがみ姿勢を初期化 --- self._set_squat_pose() self.data.qpos[2] = -0.06 mujoco.mj_forward(self.model, self.data) return self._get_obs(), {} def render(self): if self.render_mode == "human": if self.viewer is None: self.viewer = mujoco.viewer.launch_passive(self.model, self.data) self.viewer.sync() def close(self): if self.viewer is not None: self.viewer.close() self.viewer = None def __del__(self): self.close() |
30000ステップほど学習させた。
Sim2Real
学習で得た結果を実機で確認します。
実機調整
まずは久しぶりにロボット復活
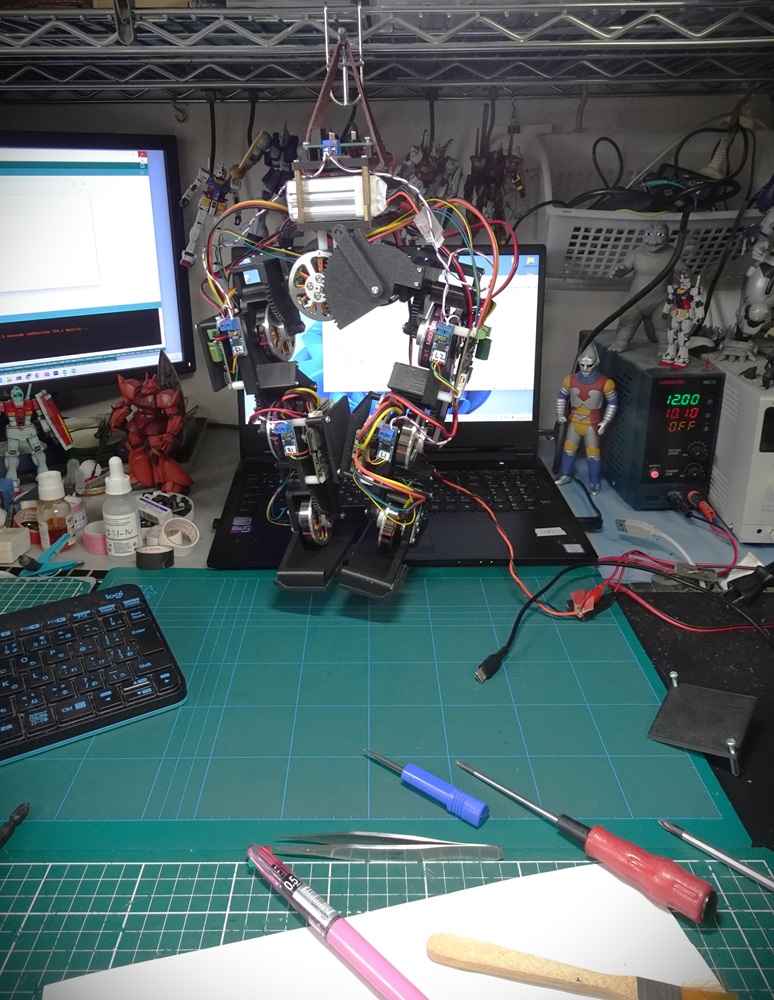
無事に動くことを確認いたしました。
ロボット復帰
さて学習結果で動かせるべか#強化学習への道#ReinforcementLearning pic.twitter.com/8YGhvF9D3I— HomeMadeGarbage (@H0meMadeGarbage) June 3, 2025
姿勢や関節の正負がSimと一致するように調整
機体や関節の角度
モデルと実機の符号擦り合わせた#強化学習への道#ReinforcementLearning pic.twitter.com/Iq8ArfELGG— HomeMadeGarbage (@H0meMadeGarbage) June 3, 2025
エンコーダ値取得
学習ではIMUの姿勢角のほかに関節の角度も観測しているため実機でも関節角度の実測値を得る必要があります。
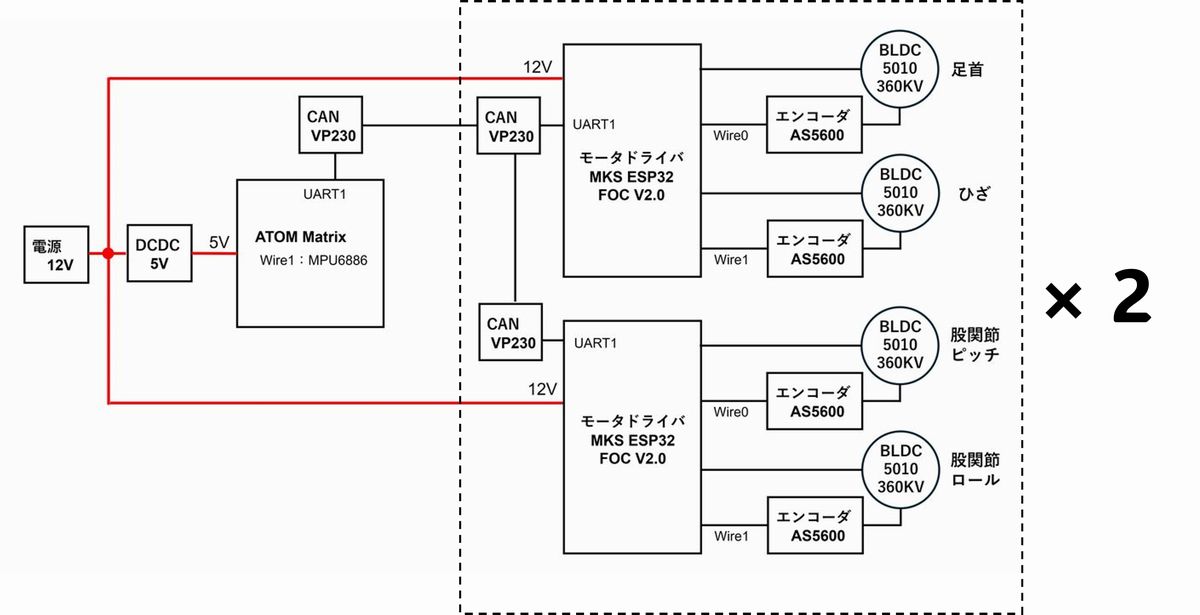
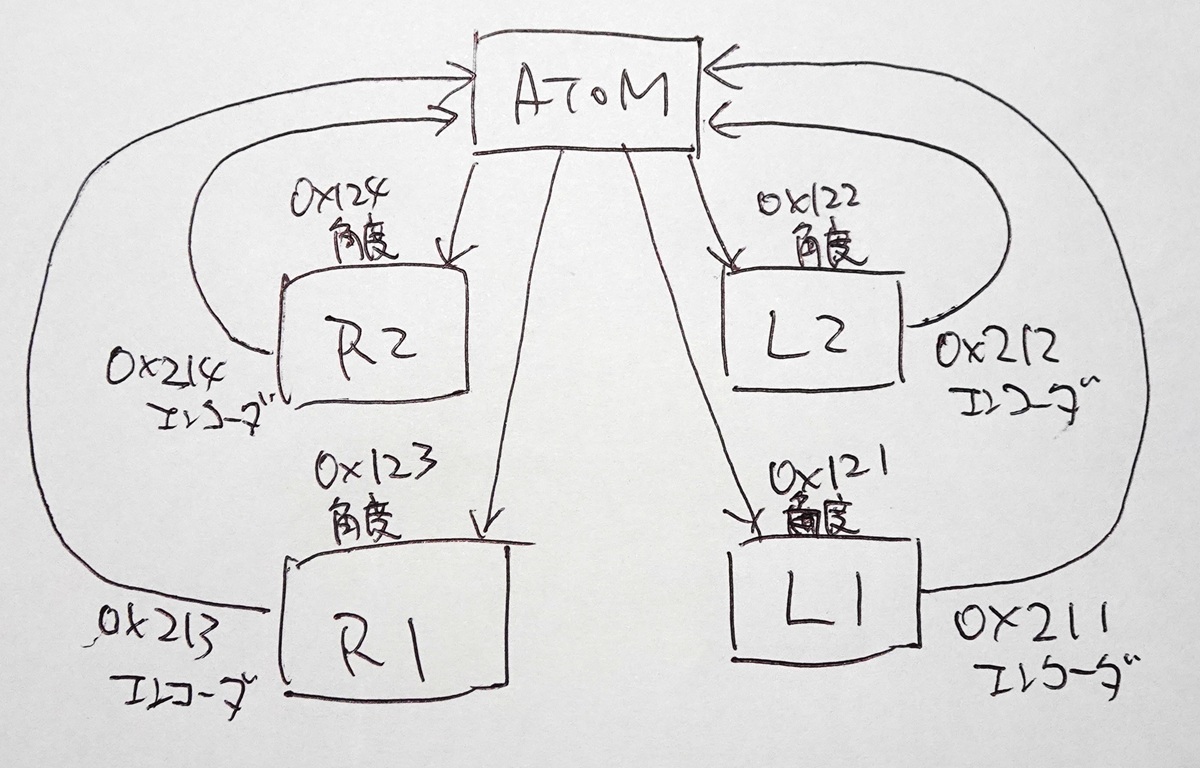
本ロボの構成は以下の通りでモータエンコーダ値をCAN通信で中枢コントローラATOMに送信するようにしました。
関節角度ゲット成功
エンコーダ値も入手できるようになりました。#強化学習への道#ReinforcementLearning pic.twitter.com/npljnwbloi
— HomeMadeGarbage (@H0meMadeGarbage) June 4, 2025
CAN通信システムは以下の通り
Sim2Real
実機の調整ができたので学習結果で動作させました。
二足歩行ロボット
Sim2Real中腰できたけどもう少し分かりやすい動作で比較するか
足のすべりとかもモデルに入れないとだな#強化学習への道#ReinforcementLearning pic.twitter.com/Ttx8b8NhTU
— HomeMadeGarbage (@H0meMadeGarbage) June 4, 2025
動画だと非常に分かりにくいけど、押すと反発するように足を動かしてくれてます。
地味だけど2足歩行ロボットのSim2Real成功
ファインチューン
バランス動作のSim2Realが分かりにくかったので、学習結果を引き継いでさらに外乱に強く足を大胆に動かすようにします。
環境コードは以下
リセット時のピッチ角外乱を大きくして、傾いたときに足をより前後させるようにしました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 |
import gymnasium as gym from gymnasium import spaces import numpy as np import mujoco from mujoco_model import get_model_xml import math class BipedalStandEnv(gym.Env): def _set_squat_pose(self): target_angles = np.radians([-50, 100, -50, 0, -50, 100, -50, 0]) angle_ids = [self.model.jnt_qposadr[i] for i in self.joint_ids] for i, qid in enumerate(angle_ids): self.data.qpos[qid] = target_angles[i] mujoco.mj_forward(self.model, self.data) def __init__(self, render_mode=None): self.model = mujoco.MjModel.from_xml_string(get_model_xml()) self.data = mujoco.MjData(self.model) self.render_mode = render_mode self.viewer = None self.dt = self.model.opt.timestep self.time = 0.0 self.np_random = np.random.default_rng() self.hip_site = mujoco.mj_name2id(self.model, mujoco.mjtObj.mjOBJ_SITE, "hip") self.footL_site = mujoco.mj_name2id(self.model, mujoco.mjtObj.mjOBJ_SITE, "footL") self.footR_site = mujoco.mj_name2id(self.model, mujoco.mjtObj.mjOBJ_SITE, "footR") self.hip_id = mujoco.mj_name2id(self.model, mujoco.mjtObj.mjOBJ_BODY, "hip") self.observation_space = spaces.Box( low=np.array( [-math.radians(80), -math.radians(80), -math.radians(250), -math.radians(250)] + [-math.radians(90)] * 8, dtype=np.float32 ), high=np.array( [math.radians(80), math.radians(80), math.radians(250), math.radians(250)] + [math.radians(90)] * 8, dtype=np.float32 ), dtype=np.float32 ) self.action_space = spaces.Box( low=np.full(8, -1.0, dtype=np.float32), high=np.full(8, 1.0, dtype=np.float32), dtype=np.float32 ) joint_names = [ "legL1_joint", "legL2_joint", "hipLpitch_joint", "hipLroll_joint", "legR1_joint", "legR2_joint", "hipRpitch_joint", "hipRroll_joint" ] self.joint_ids = [ mujoco.mj_name2id(self.model, mujoco.mjtObj.mjOBJ_JOINT, name) for name in joint_names ] self.angle_ids = np.array([self.model.jnt_qposadr[i] for i in self.joint_ids]) self.velocity_ids = np.array([self.model.jnt_dofadr[i] for i in self.joint_ids]) self._set_squat_pose() self.data.qpos[2] = -0.06 mujoco.mj_forward(self.model, self.data) def xmat_to_euler(self): xmat = self.data.xmat[self.hip_id] r00, r01, r02 = xmat[0], xmat[1], xmat[2] r10, r11, r12 = xmat[3], xmat[4], xmat[5] r20, r21, r22 = xmat[6], xmat[7], xmat[8] if abs(r20) < 1.0: roll = -math.asin(r20) pitch = math.atan2(r21, r22) else: pitch = math.pi / 2 * np.sign(-r20) roll = 0 return pitch, roll def _get_obs(self): pitch, roll = self.xmat_to_euler() pitch_vel = self.data.qvel[3] roll_vel = self.data.qvel[4] gear_angles = self.data.qpos[self.angle_ids] obs = np.concatenate(( np.array([pitch, roll, pitch_vel, roll_vel], dtype=np.float32), gear_angles.astype(np.float32) )) return obs def step(self, action): # --- time更新 --- self.time += self.dt # [-1,1] → ctrlrangeに変換 # ctrlrange = self.model.actuator_ctrlrange[:8] # low, high = ctrlrange[:, 0], ctrlrange[:, 1] # self.data.ctrl[:8] = low + (action + 1.0) * 0.5 * (high - low) center = np.radians([-50, 100, -50, 0, -50, 100, -50, 0]) scale = np.radians([50, 50, 50, 5, 50, 50, 50, 5]) # ±スケーリング幅 self.data.ctrl[:8] = center + action * scale mujoco.mj_step(self.model, self.data) obs = self._get_obs() pitch, roll, pitch_vel, roll_vel = obs[:4] gear_angles = obs[4:12] # 報酬 reward = ( - pitch**2 - roll**2 - 0.01 * pitch_vel**2 - 0.01 * roll_vel**2 ) # しゃがみ角度との一致を報酬に(強力) target_angles = np.radians([-50, 100, -50, 0, -50, 100, -50, 0]) reward -= 5.0 * np.sum((gear_angles - target_angles) ** 2) # 静止安定化ボーナス if abs(pitch) < math.radians(1) and abs(roll) < math.radians(1): reward += 30.0 footL_pos = self.data.site_xpos[self.footL_site] footR_pos = self.data.site_xpos[self.footR_site] # ✨転倒しかけた時に足が前に出ていたらご褒美 if angle_penalty := (pitch**2 + roll**2) > math.radians(5)**2: foot_forward_L = footL_pos[1] > 0.03 foot_forward_R = footR_pos[1] > 0.03 if foot_forward_L or foot_forward_R: reward += 50.0 hipZ = self.data.site_xpos[self.hip_site][2] # hipZの目標値との差に基づいた報酬 reward -= 3000.0 * (hipZ - 0.16)**2 # --- ログ --- print(f"[STEP] time={self.time:.3f}, pitch={np.degrees(pitch):>6.2f}, roll={np.degrees(roll):>6.2f}, hipZ={hipZ:.4f}, reward={reward:6.3f}") #print(f"pitch={pitch:.2f}, roll={roll:.2f}, pitch_vel={pitch_vel:.2f}, roll_vel={roll_vel:.2f}, qpos[0:7]={self.data.qpos[0:7]}s") # 終了条件 転倒 terminated = ( abs(pitch) > math.radians(45.0) or abs(roll) > math.radians(45.0) ) truncated = False if self.time > 45.0: truncated = not terminated terminated = False # 転倒じゃない終了として扱う return obs, reward, terminated, truncated, {} def reset(self, seed=None, options=None): super().reset(seed=seed) mujoco.mj_resetData(self.model, self.data) self.time = 0.0 self.data.qpos[0:3] = np.array([0.0, 0.0, 0.0]) self.data.qvel[0:6] = 0.0 pitch_offset = self.np_random.uniform(-math.radians(30), math.radians(30)) roll_offset = self.np_random.uniform(-math.radians(5), math.radians(5)) quat = np.zeros(4, dtype=np.float64) euler = np.array([pitch_offset, roll_offset, 0.0], dtype=np.float64) mujoco.mju_euler2Quat(quat, euler, "xyz") self.data.qpos[3:7] = quat self._set_squat_pose() self.data.qpos[2] = -0.06 mujoco.mj_forward(self.model, self.data) self.initial_footL_pos = np.copy(self.data.site_xpos[self.footL_site][:2]) self.initial_footR_pos = np.copy(self.data.site_xpos[self.footR_site][:2]) self.prev_angle_penalty = None return self._get_obs(), {} def render(self): if self.render_mode == "human": if self.viewer is None: self.viewer = mujoco.viewer.launch_passive(self.model, self.data) self.viewer.sync() def close(self): if self.viewer is not None: self.viewer.close() self.viewer = None def __del__(self): self.close() |
学習時に reset_num_timesteps=False としないと元の学習を引き継がずに位置から学習してしまうので要注意。
これで何日も無駄にした。
reset_num_timesteps=Falseで学習すると前回の学習ステップ30000を引き継いでファインチューン環境ファイルをもとにさらにステップが追加されます。
Sim2Real
ファインチューン結果を実機で確認
バランス動作
足を前に出すようにしたいけどどうしても学習がうまくいかない#強化学習への道#ReinforcementLearning pic.twitter.com/iZQFQ1aWEH— HomeMadeGarbage (@H0meMadeGarbage) June 14, 2025
よりアグレッシブに足が動くようになった。まだ少し地味だけど
もっと傾いたら足を1,2歩出すようにしたかったけど、どうしても学習がうまくいきませんでした。
どういう報酬あげればいいんだろ??
おわりに
ここではついに2足歩行ロボットの強化学習Sim2Realを確認しました。
バランス動作させるだけでかなり時間がかかりました。
報酬の与え方などまだまだ勉強する必要があります。
ここから歩行させるのはかなり難しそうです。計算量も半端なくなりそう。。
理想的な歩行を作りこんで外乱などの変数を強化学習で振るなどの模倣学習ベースが現実的なような気がしてきています。
ひとまず実機検証も可能な学習モデルや環境ができたので、改めて方針を整えたいと思います。
それではまた