2足歩行ロボット HM-01 の強化学習2
本記事にはアフィリエイト広告が含まれます。
2足歩行ロボット HM-01 の足踏みバランス動作を目指して強化学習の実施を決意いたしました。
前回は強化学習の計算時間短縮をめざしてGPU活用とCPU並列化の検討しました。
強化学習からSim2Sim~Sim2Real 実現の観点から、ひとまず従来手法をCPU並列化で高速化するという結論にいたりました。

目次
論文調査
足踏み動作をさせるための強化学習の方法がわからなかったので論文を調査しました。
コチラの論文が非常に参考になりました。

ヒューマノイドをNVIDIA の Isaac Gym をベースで学習して、そのまま (“zero-shot”) Sim2Realできる手法が紹介されています。
GitHub:https://github.com/roboterax/humanoid-gym/tree/main
報酬記述:humanoid_env.py
論文の表Ⅳにヒューマノイド強化学習の報酬について記載があります。
・並進速度トラッキング(重み 1.2):ロボット胴体の移動速度を指令値に合わせる。
・角速度トラッキング(重み 1.0):胴体の回転速度を指令値に合わせる
・姿勢トラッキング(重み 1.0):ロール・ピッチ・ヨーの角度を維持する
・ベース高さトラッキング(重み 0.5):胴体のさを目標(0.7m)に保つ
・速度ミスマッチ(重み 0.5):現在速度とコマンド速度のズレを罰する
・接触パターン(重み 0.2):足の接地状態が期待されるパターンから外れないようにする
・関節位置トラッキング(重み 1.5):関節角度が目標角度に近づくようにする
・デフォルト関節(重み 0.2):関節が初期・基準姿勢から大きく離れないようにする。
・エネルギーコスト(重み -0.00001):トルクと角速度に応じて小さくペナルティを与える
・アクションのスムーズさ(重み -0.01):急激な行動変化を抑制する
・大きな接触ペナルティ(重み -0.01):床反力が一定値を超えた場合に罰則を与える
基本姿勢保持や低消費エネルギーの評価に加えて、コントローラによる指令値やリファレンスモーションへの追従にも報酬が付与されていました。
足踏みや歩行動作はあらかじめモーションを用意する必要があるようです。
ディズニーのBDX Droidの論文でもリファレンスモーションを模倣することに報酬を与えて、それに省エネや転倒しないことへの報酬をくわえて学習しています (表1)。
そっかー純粋に強化学習のみで歩き出すわけじゃないのかぁ。。
報酬の設計の仕方によってはリファレンスなしでも歩き出すかもしれないど、相当時間かかるだろうし、
基本動作は用意して学習で外乱に強くしたり機体バラつきに対応したり外部制御できるようにするのがスマートなんですね。
勉強になりました。
強化学習
論文を参考にHM-01の強化学習を進めます。
Gymnasiumベースの強化学習環境を、Stable-Baselines3(PPO )で学習します。
以下の直立バランス学習をベースに足踏みバランス動作を目指します。
報酬にベースbody高さ保持を追加
だいぶいいけど
ピッチ傾きに対して足前に出すとかしてほしな
足踏み学習させないと無理か#強化学習への道2 #ReinforcementLearning pic.twitter.com/b98FN8oCZW— HomeMadeGarbage (@H0meMadeGarbage) October 6, 2025
ちなみにコレは以下の報酬で学習を実施しました。
・ベースボディのピッチ、ロールの角度・角速度をゼロに保持
・各関節を初期姿勢に強制保持
・ピッチ、ロールの角度 1°以内に保持でボーナス
・ベースボディ高さ保持
報酬追加① 足踏みリファレンスモーション
正弦波形で足の高さを左右逆相で交互に変えて足踏みモーション生成し、IKでモータ角度を算出して追従するように報酬を加えました。
報酬に足踏みリファレンスモーション追従を追加
強化学習で足踏みできた
IKで正弦波形で足踏みモーション生成してモータ角度追従しなけりゃペナルティよでも思ったような外乱対応じゃないな
もっと意地悪な学習しないとかな#強化学習への道2 #ReinforcementLearning pic.twitter.com/GGAo0N7qbK— HomeMadeGarbage (@H0meMadeGarbage) October 6, 2025
足踏みできた!
やはりリファレンスモーションが必要なのねぇ
HM-01についてはすでに手製のモーションがあり実機で動かしてるからいいけど
新規のロボット設計の際に強化学習ってどのくらい使えるのかね?と疑問も増えました。
だから既存ロボのデータもセットの学習フレームワークで溢れてるのか??
まぁとりあえず足踏みがニューラルネットワークで実現できたのは大きな前進です。
しかし、Sim.でみると外乱にはまだ弱い様子。
報酬追加② ボディ並進速度
ベースボディの並進速度 (Vx, Vy, Vz)がゼロに保持されるように報酬を追加
報酬重み調整とかでそろそろ気が狂いそうなので
いったんこれでSim2Realいきますかぁ#強化学習への道2 #ReinforcementLearning pic.twitter.com/cDfb2ljbFJ— HomeMadeGarbage (@H0meMadeGarbage) October 7, 2025
かなりいい感じに外乱にも対応できるようになりました。
ニューラルネットワーク
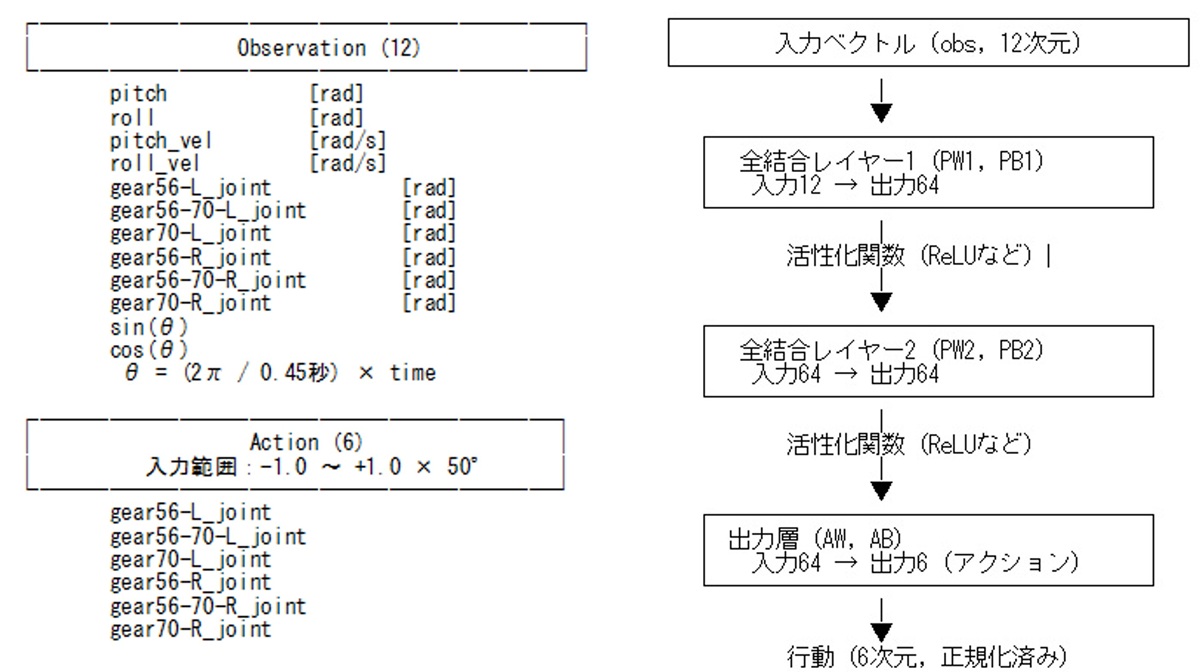
今回のニューラルネットワーク構成は「64×64の全結合2層MLP」で、入力(観測ベクトル)と出力(行動ベクトル)は以下の通りです。
観測ベクトル(obs)12次元
・ピッチ角、ロール角 [rad]
・ピッチ角速度、ロール角速度 [rad/s]
・左足3軸の各モータの回転位置角度 [rad]
・右足3軸の各モータの回転位置角度 [rad]
・ sin(θ)
・ cos(θ)
※ θ = (2π ÷ 0.45秒) × time
時間経過による周期フェーズをsin・cosに変換して入力することで、
0と2πの不連続を避けて学習を安定化させています。
行動ベクトル(action)6次元
・左足3軸の各モータの回転位置角度 [rad]
・右足3軸の各モータの回転位置角度 [rad]
各要素 -1.0 ~ +1.0 で正規化されて出力される
学習時は50°をかけてスケーリング
Sim2Real
学習データを実機HM-01に移植して動作確認します。
要するにSim2Realします。
実機
HM-01 初号機を使用
初号機を2号機風に回収
少しモダンになったしかしSim2Real用にファームほぼ総とっかえだろうね pic.twitter.com/bYHOBDt0iz
— HomeMadeGarbage (@H0meMadeGarbage) October 7, 2025
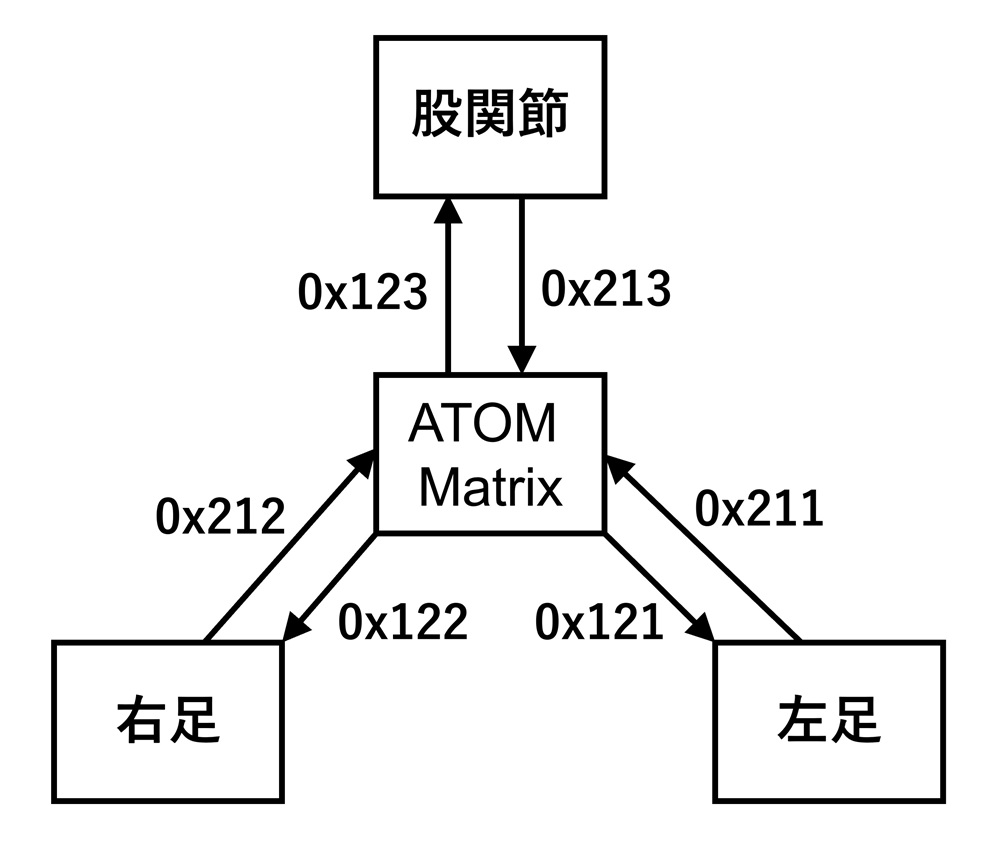
入力(観測ベクトル)の角度・角速度は実機のIMUデータを使用します。
各モータの角度はエンコーダ値をCANで中枢マイコンATOM Matrixに送信します。
周期フェーズのsin・cosはATOM Matrixのカウンタで算出してニューラルネットワークに入力します。
観測ベクトルの入力で得られた行動ベクトルのモータ回転位置を各ドライバにCANで送信します。
実機のCANシステムをSim2Real用に以下のようにしました。
学習データ
Stable-Baselines3で得たzipファイル学習データをESP32用に配列に変換して移植します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
static const float PW1[64][12] = {......}; static const float PB1[64] = {......}; static const float PW2[64][64] = {......}; static const float PB2[64] = {.......}; static const float AW[6][64] = {.......}; static const float AB[6] = {-0.19107375, -0.06273635, -0.04636306, -0.19063123, -0.06873517, 0.04059920}; // 固定次元(可読性と事故防止) enum { OBS_DIM = 12, H1_DIM = 64, H2_DIM = 64, ACT_DIM = 6 }; // ReLU(float版) static inline float relu(float x) { return x > 0.0f ? x : 0.0f; } // 内積(float版) static inline float dot(const float* a, const float* b, int size) { float sum = 0.0f; for (int i = 0; i < size; ++i) sum += a[i] * b[i]; return sum; } void forward(const float obs[OBS_DIM], float* action_out) { float h1[H1_DIM]; float h2[H2_DIM]; // Layer 1: obs(12) -> h1(64) for (int i = 0; i < H1_DIM; ++i) { h1[i] = relu(dot(PW1[i], obs, OBS_DIM) + PB1[i]); } // Layer 2: h1(64) -> h2(64) for (int i = 0; i < H2_DIM; ++i) { h2[i] = relu(dot(PW2[i], h1, H1_DIM) + PB2[i]); } // Output: h2(64) -> action(6), 出力は[-1, 1]に収める(環境がtanh前提) for (int i = 0; i < ACT_DIM; ++i) { action_out[i] = tanhf(dot(AW[i], h2, H2_DIM) + AB[i]); } } |
forward関数に12個の入力を入れると出力の各モータの回転位置が導出されます。
変換はいつもChatGPTにやってもらっています。
ありがとうChatGPT
Sim2Real
フィジカルAI pic.twitter.com/3WLAFTtsBn
— HomeMadeGarbage (@H0meMadeGarbage) October 10, 2025
見事に足踏みできてる!
おおむねSim.通りの動作が実機で実現できております。
Sim2Real
あたりまえだけどSim.以上の性能はでないよなぁ#フィジカルAI #PhysicalAI#強化学習への道2 #ReinforcementLearning pic.twitter.com/WGUp9PqHx1— HomeMadeGarbage (@H0meMadeGarbage) October 10, 2025
HM-01 のMJCFモデルも大きく外していないことも立証できたので安心いたしました。
と同時にもっと外乱耐性を上げたいという欲も湧いてきたのです。
Re 強化学習
外乱への強度を高めることを目的に再度 強化学習します。
報酬追加③
・外乱として前後方向とピッチ角にランダムで外乱注入
・ベース高さ保持報酬廃止
・モータトルクによる省エネ報酬追加
・ベースボディの並進速度 (Vx, Vy, Vz)ゼロ保持でVy(前後方向)のみ廃止
・転倒せずの生存ボーナス追加
・ベースボディの傾斜に応じて足前後(P制御)追加
散歩終わり玄関前にて pic.twitter.com/lKdK695uve
— HomeMadeGarbage (@H0meMadeGarbage) October 10, 2025
Sim.上では外乱に強なったで (前後方向のみ特化型だけど)
Sim2Real
実機でも外乱耐性向上を確認できました。
Sim2Real
だいぶ外乱に強くなったね#フィジカルAI #PhysicalAI#強化学習への道2 #ReinforcementLearning pic.twitter.com/8KRtbFfikV— HomeMadeGarbage (@H0meMadeGarbage) October 12, 2025
ついに強化学習で思い通りの結果が得られるようになってきました。
学習環境クラスファイル
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 |
import gymnasium as gym from gymnasium import spaces import numpy as np import mujoco from mujoco_model import get_model_xml import math class BipedalStandEnv(gym.Env): def _set_squat_pose(self): # ベース高さ z_base = 0.099 x_offset = 0.01 targetL = self.ik_leg(x_offset, z_base) targetR = self.ik_leg(x_offset, z_base) target_angles = np.zeros(6, dtype=np.float64) target_angles[0] = targetL[0] target_angles[1] = targetL[1] target_angles[3] = targetR[0] target_angles[4] = targetR[1] angle_ids = [self.model.jnt_qposadr[i] for i in self.joint_ids] for i, qid in enumerate(angle_ids): self.data.qpos[qid] = target_angles[i] mujoco.mj_forward(self.model, self.data) def __init__(self, render_mode=None): self.model = mujoco.MjModel.from_xml_string(get_model_xml()) self.data = mujoco.MjData(self.model) self.render_mode = render_mode self.viewer = None self.dt = self.model.opt.timestep self.time = 0.0 self.period = 0.5 self.omega = 2.0 * math.pi / self.period self.gait_phase0 = 0.0 self.np_random = np.random.default_rng() self.hip_id = mujoco.mj_name2id(self.model, mujoco.mjtObj.mjOBJ_BODY, "body") self.observation_space = spaces.Box( low=np.array( [-math.radians(90), -math.radians(90), -math.radians(250), -math.radians(250)] + [-math.radians(90)] * 6 + [-1.0, -1.0], # ★ 追加 +2 次元(sin/cos) dtype=np.float32 ), high=np.array( [ math.radians(90), math.radians(90), math.radians(250), math.radians(250)] + [ math.radians(90)] * 6 + [ 1.0, 1.0], # ★ 追加 +2 次元(sin/cos) dtype=np.float32 ), dtype=np.float32 ) self.action_space = spaces.Box( low=np.full(6, -1.0, dtype=np.float32), high=np.full(6, 1.0, dtype=np.float32), dtype=np.float32 ) joint_names = [ "gear56-L_joint", "gear56-70-L_joint", "gear70-L_joint", "gear56-R_joint", "gear56-70-R_joint", "gear70-R_joint" ] self.joint_ids = [ mujoco.mj_name2id(self.model, mujoco.mjtObj.mjOBJ_JOINT, name) for name in joint_names ] self.angle_ids = np.array([self.model.jnt_qposadr[i] for i in self.joint_ids]) self._set_squat_pose() mujoco.mj_forward(self.model, self.data) @staticmethod def ik_leg(x, z): L = 0.07 ld = np.sqrt(x**2 + z**2) if ld > 2 * L: return None # 足が伸びすぎて到達不能 th1d = np.arccos(ld / (2 * L)) th2d = np.arccos((2 * L * L - ld * ld) / (2 * L * L)) phi = np.arctan2(x, z) th1 = phi + th1d # 股関節側の角度 th2 = (math.pi - th2d) - th1 th1 = -th1 + math.pi / 4.0 th2 = th2 - math.pi / 4.0 if any(np.isnan([th1, th2])): return None return th1, th2 def xmat_to_euler(self): # 回転行列(3x3)を取得(9要素 flat) xmat = self.data.xmat[self.hip_id] r00, r01, r02 = xmat[0], xmat[1], xmat[2] r10, r11, r12 = xmat[3], xmat[4], xmat[5] r20, r21, r22 = xmat[6], xmat[7], xmat[8] # Z-Y-X順(Y軸がroll、X軸がpitch) if abs(r20) < 1.0: roll = -math.asin(r20) # Y軸回転(左右)=ロール pitch = math.atan2(r21, r22) # X軸回転(前後)=ピッチ else: pitch = math.pi / 2 * np.sign(-r20) roll = 0 return pitch, roll def _get_obs(self): pitch, roll = self.xmat_to_euler() # x軸=ピッチ, y軸=ロール # baseの角速度(qvel[3] = x軸回転、qvel[4] = y軸回転) pitch_vel = self.data.qvel[3] roll_vel = self.data.qvel[4] # 関節角度・速度(joint_ids ベース) gear_angles = self.data.qpos[self.angle_ids] # 観測値を1つのベクトルにまとめる obs = np.concatenate(( np.array([pitch, roll, pitch_vel, roll_vel], dtype=np.float32), gear_angles.astype(np.float32) )) theta = self.omega * self.time + self.gait_phase0 phase_feat = np.array([math.sin(theta), math.cos(theta)], dtype=np.float32) obs = np.concatenate((obs, phase_feat)).astype(np.float32) return obs def step(self, action): # --- time更新 --- self.time += self.dt self.data.ctrl[:6] = action * np.radians(50) # === 外乱注入セクション === #5%の確率で外乱を与える(平均0, 範囲±force_scale) if np.random.rand() < 0.05: force_scale = 20.0 # N(調整可能) torque_scale = 5.0 # Nm fx, fy, fz = self.np_random.uniform(-force_scale, force_scale, 3) tx, ty, tz = self.np_random.uniform(-torque_scale, torque_scale, 3) self.data.xfrc_applied[self.hip_id, 0:3] = [0.0, fy, 0.0] #平行力 [Fx, Fy, Fz] self.data.xfrc_applied[self.hip_id, 3:6] = [tx, 0.0, 0.0] #回転トルク [Tx, Ty, Tz] else: # 外力をリセット self.data.xfrc_applied[self.hip_id, :] = 0.0 # =========================== mujoco.mj_step(self.model, self.data) obs = self._get_obs() pitch, roll, pitch_vel, roll_vel = obs[:4] gear_angles = obs[4:10] hip_height = self.data.xpos[self.hip_id][2] theta = self.omega * self.time + self.gait_phase0 z_base = 0.099 z_ampl = 0.015 zL = z_base + z_ampl * math.sin(theta) zR = z_base - z_ampl * math.sin(theta) xL_offset = -0.01 * abs(pitch) * math.cos(theta) xR_offset = 0.01 * abs(pitch) * math.cos(theta) targetL = self.ik_leg(xL_offset + 0.01, zL) targetR = self.ik_leg(xR_offset + 0.01, zR) # 報酬 reward = ( - pitch**2 - roll**2 - 0.01 * pitch_vel**2 - 0.01 * roll_vel**2 ) # 角度との一致を報酬に(強力) target_angles = np.radians([0, 0, 0, 0, 0, 0]) target_angles[0] = targetL[0] target_angles[1] = targetL[1] target_angles[3] = targetR[0] target_angles[4] = targetR[1] reward -= 500.0 * np.sum((gear_angles - target_angles) ** 2) # --- エネルギー使用ペナルティ --- torque = self.data.ctrl[:6] # 各関節トルク [Nm] reward -= 1.0 * np.sum(torque ** 2) # トルクの2乗和(0.001は重み係数) # --- hip 並進速度トラッキング報酬 --- hip_v = np.array(self.data.cvel[self.hip_id][3:6], dtype=np.float32) # vx, vy, vz cmd_v = np.array([0.0, 0.0, 0.0], dtype=np.float32) # 目標速度 reward -= 300.0 * (hip_v[0] ** 2 + hip_v[2] ** 2) # y,zは罰するがxは許容 # --- ログ --- #print(f"[STEP] time={self.time:.3f}, pitch={np.degrees(pitch):>6.2f}, roll={np.degrees(roll):>6.2f}, reward={reward:6.3f}") print( f"[STEP] time={self.time:.3f}, " f"pitch={np.degrees(pitch):>6.2f}, " f"roll={np.degrees(roll):>6.2f}, " f"pitch_vel={np.degrees(pitch_vel):>6.2f}, " f"roll_vel={np.degrees(roll_vel):>6.2f}, " f"hip_z={hip_height:.4f}, " f"reward={reward:6.3f}" ) # 終了条件 転倒 terminated = ( abs(pitch) > math.radians(80.0) or abs(roll) > math.radians(80.0) ) truncated = False # --- 生存ボーナス --- if not terminated: reward += 300.0 if self.time > 45.0: truncated = not terminated terminated = False # 転倒じゃない終了として扱う return obs, reward, terminated, truncated, {} def reset(self, seed=None, options=None): super().reset(seed=seed) mujoco.mj_resetData(self.model, self.data) self.time = 0.0 #初期位相をランダム化 self.gait_phase0 = self.np_random.uniform(0.0, 2.0 * math.pi) # ベース位置初期化 self.data.qpos[0:3] = np.array([0.0, 0.0, 0.0]) # x, y, z self.data.qvel[0:6] = 0.0 # --- 初期 並進速度のランダム化(m/s) --- lin_std = 0.1 # 標準偏差 (m/s) rand_lin = self.np_random.normal(0.0, lin_std, size=3).astype(np.float64) vx_vy = self.np_random.normal(0.0, lin_std, size=2).astype(np.float64) self.data.qvel[0:3] = np.array([vx_vy[0], vx_vy[1], 0.0], dtype=np.float64) # (必要なら)角速度も少しだけバラつかせる(rad/s) ang_std = math.radians(10) # 10 deg/s self.data.qvel[3:6] = self.np_random.normal(0.0, ang_std, size=3).astype(np.float64) #姿勢:わずかにランダム傾ける pitch_offset = self.np_random.uniform(-math.radians(10), math.radians(10)) roll_offset = self.np_random.uniform(-math.radians(3), math.radians(3)) quat = np.zeros(4, dtype=np.float64) euler = np.array([pitch_offset, roll_offset, 0.0], dtype=np.float64) mujoco.mju_euler2Quat(quat, euler, "xyz") self.data.qpos[3:7] = quat self._set_squat_pose() mujoco.mj_forward(self.model, self.data) return self._get_obs(), {} def render(self): if self.render_mode == "human": if self.viewer is None: self.viewer = mujoco.viewer.launch_passive(self.model, self.data) self.viewer.sync() def close(self): if self.viewer is not None: self.viewer.close() self.viewer = None def __del__(self): self.close() |
学習用スクリプト
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
# -*- coding: utf-8 -*- # train_stand_cpu_parallel_min.py # 目的: CPUだけで安定&高速に回す最小構成(SubprocVecEnv) import os import platform import multiprocessing as mp # MuJoCoの描画は学習中オフ。Windowsはglfw、Linuxはosmesaにしとけば安全。 if platform.system() == "Windows": os.environ["MUJOCO_GL"] = "glfw" else: os.environ.setdefault("MUJOCO_GL", "osmesa") # BLASのスレッド暴走を抑える(Subprocとケンカさせない) os.environ.setdefault("OMP_NUM_THREADS", "1") os.environ.setdefault("MKL_NUM_THREADS", "1") import torch torch.set_num_threads(max(1, (os.cpu_count() or 4) // 2)) # CPUの過剰並列を抑制 import gymnasium as gym from stable_baselines3 import PPO from stable_baselines3.common.vec_env import SubprocVecEnv from BipedalStandEnv import BipedalStandEnv # 自作Env # 物理コアに合わせて決める(多すぎると文脈スイッチングで遅くなる) PHYS = max(4, (os.cpu_count() or 8) // 2) # 雑だけど目安 N_ENVS = min(16, PHYS) # 4〜16の範囲で十分 def make_env(seed_offset: int = 0): def _thunk(): env = BipedalStandEnv(render_mode=None) try: env.reset(seed=1234 + seed_offset) except TypeError: if hasattr(env, "seed"): env.seed(1234 + seed_offset) return env return _thunk def main(): env = SubprocVecEnv([make_env(i) for i in range(N_ENVS)]) # CPUは大バッチの旨味が薄い → 中くらいのbatch/n_stepsで回転を上げる model = PPO( "MlpPolicy", env, policy_kwargs = {"net_arch": [64, 64], "log_std_init": 0.3}, learning_rate=3e-4, n_steps=512, # 各Envあたり。合計は N_ENVS * n_steps batch_size=512, # 256〜1024で調整。CPUならこれくらいが旨味ゾーン gamma=0.99, gae_lambda=0.95, clip_range=0.2, normalize_advantage=True, verbose=1, device="cpu", # 明示 ) model.learn(total_timesteps=1_000_000) model.save("stand_model") print("Saved") if __name__ == "__main__": try: mp.set_start_method("spawn", force=True) except RuntimeError: pass main() |
おわりに
ここでは2足歩行ロボット HM-01 の足踏みバランス動作を目指して強化学習を実施しました。
足踏み動作はリファレンスモーションとしてあらかじめ用意して学習で追従させました。
さらに外乱印加しながら姿勢保持などの報酬を与えることでバランス耐性を高めました。
ヒューマノイドロボットの強化学習ってリファレンスモーションを用意して その動作に追従するように学習させて、以下のバラつきを付与させて耐性を高めるのが主流のやり方のようですね。
- 地形・摩擦バラつき
- 機体(質量、センサ、アクチュエータなど)バラつき
- 外乱
今回は足踏みバランスのみですが、外部コントローラで移動なども学習するとなるとかなりの計算量となりそうです。
またリファレンスモーションなしでの学習も検討してみたいのですが、これもまた途方もない検討量や計算量になるでしょうねぇ。。。
ちょっと強化学習についてはこんなもんかなぁ
また新しい技術が出たら検討でいいかなぁ
オリジナルロボで報酬設計とかまじでゲロでるほど大変だから
リフレッシュの製作を楽しんでからまた戻ってくるかもしれません
ほな また