強化学習への道3 -Sim2Real-
本記事にはアフィリエイト広告が含まれます。
前回はついに強化学習に挑戦しました。
リアクションホイール姿勢制御モジュールの倒立動作を学習しシミュレーション上で実現させました。
外乱にも耐えうる学習結果を得られるようになった。
一旦これでSim2Realかまして実機でバックアノしてグルグル調整してく感じかなー#強化学習への道 pic.twitter.com/lLprDtx7eW
— HomeMadeGarbage (@H0meMadeGarbage) May 10, 2025
今回はここで得た学習結果を実機に移行して動作させる つまりSim2Realに挑戦いたします。
目次
学習モデル 実機移植
前回得た学習モデルは.zipファイル形式で
入力 (observation)が
theta:機体傾き [rad]
omega:機体角速度 [rad/s]
wheel_speed:ホイール角速度 [rad/s]
出力 (action)が
正規化されたトルク
という構成です。
ここでは学習モデルをESP32に移植してリアクションホイール姿勢制御モジュール (SHISEIGYO-1)を製作してSim2Realを目指します。
ESP32にzipデータをそのまま実装はできないので、取り扱える形式に変換します。
学習モデル変換
今回得た強化学習モデルは以下のようなニューラルネットワーク構成となっています。

このネットワークの各層の重み(weight)とバイアスを配列に変換してESP32に移植します
まず学習モデル.zipを.npzファイルに変換しました。
npz:NumPyが提供している複数の配列をまとめて保存できる圧縮形式
変換用Pythonコード (ChatGPTに作ってもらった)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from stable_baselines3 import PPO import numpy as np # zipファイルからモデル読み込み model = PPO.load("ppo_balance.zip") # 各層の重み・バイアスをNumPy形式で抽出 weights = {k: v.detach().cpu().numpy() for k, v in model.policy.state_dict().items()} # npz形式で保存 np.savez("weights.npz", **weights) print("save: weights.npz") |
得られた.npzファイルからネットワーク各層の重み・バイアスを抽出してESP32 Arduinoコードで取り扱える配列.hに変換します。
うちのよく教育されたChatGPTに.npzファイルを投げれば 重み配列を含む.hファイルが得られます。
変換された学習モデル.hは以下のとおり
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
#ifndef POLICY_NETWORK_H #define POLICY_NETWORK_H static const float PW0[64][3] = {........ }; static const float PB0[64] = {..... }; static const float PW2[64][64] = {...}; static const float PB2[64] = {... }; static const float AW[1][64] = { ... }; static const float AB[1] = { . }; #endif // POLICY_NETWORK_H float relu(float x) { return x > 0 ? x : 0; } float dot(const float* a, const float* b, int size) { float sum = 0; for (int i = 0; i < size; ++i) sum += a[i] * b[i]; return sum; } void forward(const float obs[3], float* action_out) { float h1[64]; float h2[64]; for (int i = 0; i < 64; ++i) { h1[i] = relu(dot(PW0[i], obs, 3) + PB0[i]); } for (int i = 0; i < 64; ++i) { h2[i] = relu(dot(PW2[i], h1, 64) + PB2[i]); } for (int i = 0; i < 1; ++i) { action_out[i] = tanh(dot(AW[i], h2, 64) + AB[i]); } } |
このファイルの forward(obs, action)に obsとして測定した機体傾斜、機体角速度、ホイール回転速度を入力すると
学習された推論正規化トルク (action)が得られます。
実機テスト
変換した学習モデルを ESP32 (ATOM Matrix)に実装してみました。
試しにATOM Matrix内蔵のIMU MPU6886による傾斜と傾斜角を入力して (ホイール速度は0とした)、出力を見てみました。
Sim2Realの第一歩
強化学習で得た学習データ.zipを配列に変換してESP32(AtomMatrix)に移植配列関数fはこんな感じ
正規化トルク=f(機体傾き, 機体角速度, ホイール角速度)試しにIMUデータのみ入れてみた
何となくいい感じの出力出てる#強化学習への道 #Sim2Real pic.twitter.com/0qR0YgrWXf— HomeMadeGarbage (@H0meMadeGarbage) May 10, 2025
それっぽい出力が得られましたので学習モデルの変換がうまくいったと判断しました。
姿勢制御モジュール製作
学習モデルのESP32への移植が確認できたので、ブラシレスモータ姿勢制御モジュールを製作してSim2Realを目指します。
サクッと実機製作(こんなん一瞬やで)

構成
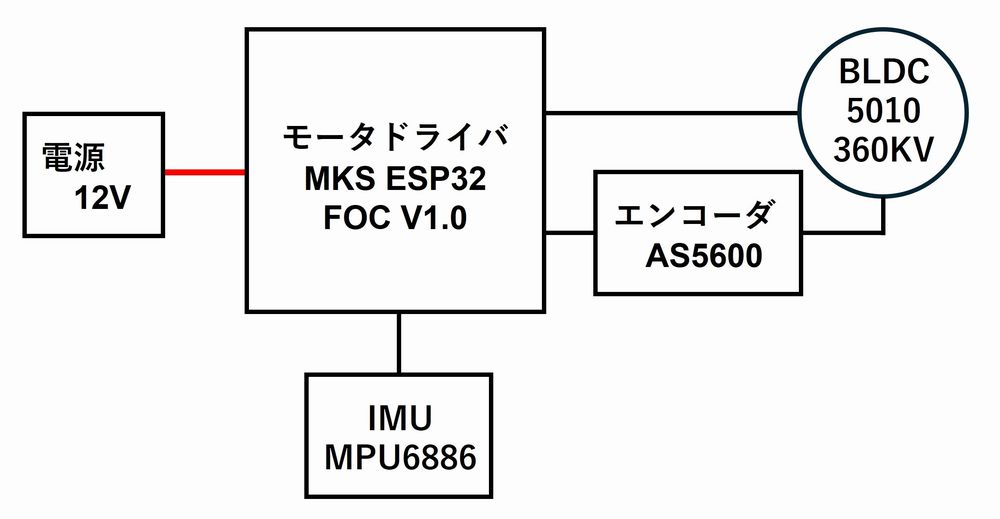
- ブラシレスモータ 5010 360KV

- 磁気エンコーダ
- ESP32搭載 モータコントローラ MKS ESP32 FOC V1.0

IMUは壊れたATOMから摘出したMPU6886を実装しました。
コントローラとはI2Cで通信

SimpleFOC
ブラシレスモータはSimpleFOCライブラリを使用して制御します。
電流ベースのベクトル制御によるトルク駆動でモータを動かします。
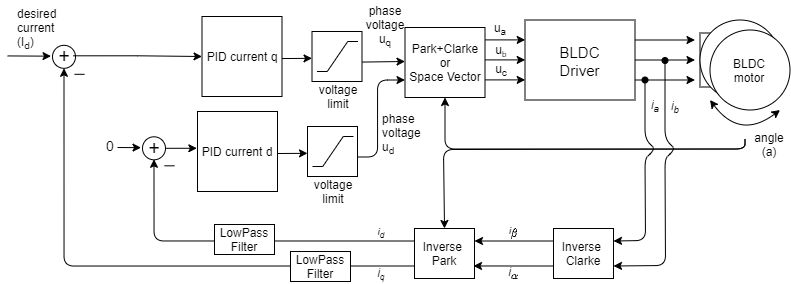
学習モデルより出力されるトルク値でモータを駆動します。
古典制御で倒立確認
製作したモジュール SHISEIGYO-1の倒立動作をまずはいつものフィードバックゲイン手動調整にて確認しました。
はい いつもの古典フィードバック
Sim2Real検証は明日のご馳走とす#強化学習への道 #ReinforcementLearning#SimpleFOC pic.twitter.com/2IJAF98fcC— HomeMadeGarbage (@H0meMadeGarbage) May 10, 2025
ブラシレスモータのロータをリアクションホイールとして問題なく倒立できました。
フィードバックの式は以下のとおり
モータトルク = Kp * 機体角度 + Kd * 機体角速度 + Kw * モータ回転速度
Sim2Real
学習モデルのESP32移植と倒立動作可能な実機が用意できましたので、いよいよSim2Realに挑戦です。
先ほど学習モデルから抽出したニューラルネットワークの配列ファイルをモータコントローラのESP32に実装し、IMUによる機体傾斜角度・角速度とSimpleFOC駆動で得られるホイール回転速度を関数に入力して得られた推定トルクでモータを駆動します。
強化学習でリアクションホイールの倒立成功!!
モデル精度や学習追い込めばよりよくなると思う
不安だったBLDCのモデル化もそこまで追いかけなくて良さそう
トルク定数とジョイントの摩擦しか指定してないけど十分っぽいわ#強化学習への道 #Sim2Real#ReinforcementLearning pic.twitter.com/4nElc2qVbG— HomeMadeGarbage (@H0meMadeGarbage) May 11, 2025
できた!
学習モデルで得られる推定トルクは±1で正規化されているので上の動画では3倍してモータを駆動しています。
ついにSim2Realができました。
倒立動作を強化学習して得られたモデルで実機でも倒立が実現しました。
Real2Sim
Sim2Realを体験できたので、この動作をうけて再度シミュレーションにフィードバックをかけて精度を上げたいと思います。
筐体精度向上
前回の強化学習で用いたsim用モデルと実機では若干形状が異なったり、制御ボードが追加されたりしているので再度Sim用モデルを作り直しました。

MuJoCoシミュレータ用の物理モデルを記述フォーマット (MJCF[MuJoCo XML Configuration File]) ではモデルの重量と重心位置と慣性モーメントまで指定できます。
各モデルの物性情報はFusin360で素材を指定することで得ることができます。
そこで得た物性情報を実機の質量でスケーリングして入力して精度を上げました。
モータモデル
モータ全体の質量は80gですがロータと固定部のそれぞれの重量は不明なのでザックリ半々で分けました。
モータの駆動系のモデルはMuJoCoのモータアクチュエータのトルク定数gearと回転部のjointの摩擦係数dampingで表現しています。
前回の強化学習ではそれぞれ gear = 0.0265、damping = 0.00005としました。
先ほどのSim2Realでほぼ問題なく倒立ができたのでモータの駆動系モデルは大きく外れていない印象でした。
逆に言うとBLDCはギアを有するサーボモータなどに比べてモデル化がしやすいのだと感じました。
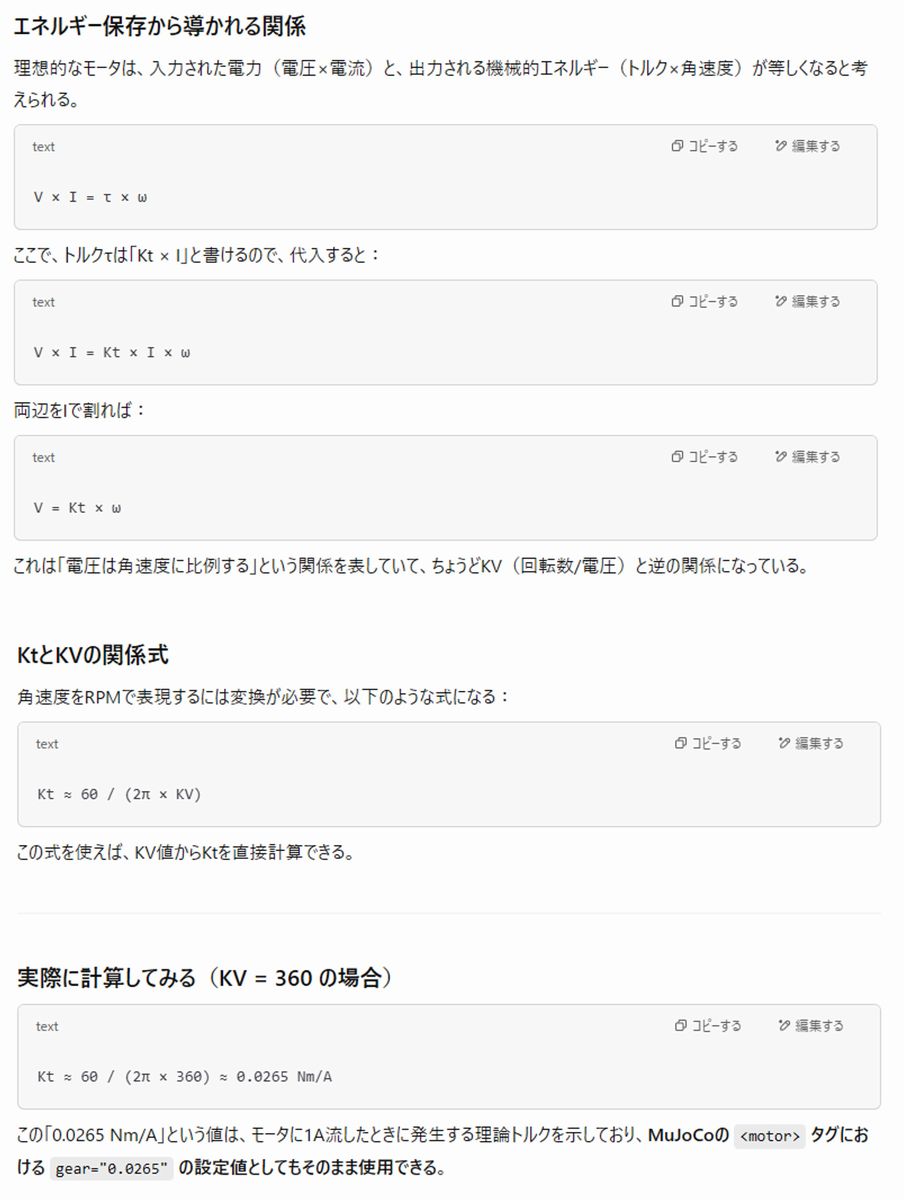
トルク定数 gear
gearの値 0.0265 はモータのKV値 360から算出
摩擦係数 damping
この値は大きすぎるとモータが回らないなどの弊害はありましたが
0.00005という小さい値だと0でも倒立の学習に影響はありませんでした。
しかしdamping 0だと回転中にトルクを0にしても慣性で延々回りすぎるのが気持ち悪かったので程よく止まる0.00005としました。
再 強化学習
実機に近い筐体モデルで再度 強化学習します。
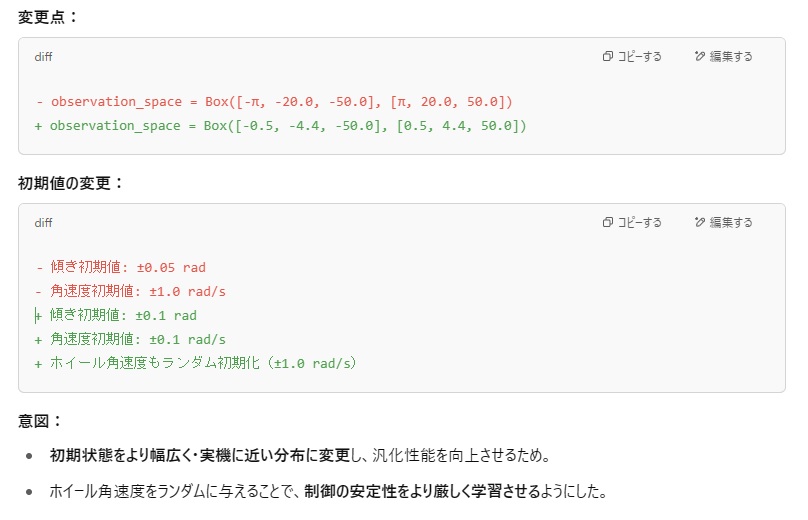
Sim2Realの結果をうけてGymnasium学習環境定義も変更しました。
観測空間と初期状態の修正
|
観測値 |
意味 |
範囲の意味 |
|
theta |
本体の傾き |
±0.5 rad ≒ ±30度(倒立限界、安定学習向け) |
|
omega |
本体の角速度 |
±4.4 rad/s(MPU6886の設定測定レンジ ±250 deg/s) |
|
wheel_speed |
ホイール角速度 |
±50 rad/s |
報酬関数の変更
|
1 2 3 4 5 6 7 |
reward = ( - 5.0 * theta**2 - 0.1 * omega**2 + 5.0 * (abs(theta) < 0.01) - 0.1 * (np.sign(theta) != np.sign(wheel_speed)) # + 30.0 * delta_theta ) |
delta_theta = abs(prev_theta) – abs(theta) で前のステップの傾斜角の差をとって
倒立に近づいたら報酬付与を追加
再 Sim2Real
再強化学習の結果と実機移行の結果が以下のとおりです。
Simで外乱なども模擬してみましたが、転倒の仕方もクリソツで物理シミュレータの凄さを感じました。
ブラシレスモータのモデル化に不安がありましたが概ね動作できているのでMuJoCoのmotorアクチュエータのgear値とジョイントの摩擦係数dampingのみでもいけてるようです。
モータ物理モデルもざっくりで作りましたが問題なく倒立動作の再現ができているので、このブラシレスモータに置いては良いモデル化ができたのかと考えております。
更なる細かい調整は学習ではなく推定トルクに係数をかけるなどの微調整で十分実機動作にかなう印象です。
おわりに
ここでは強化学習結果を実機に移行してSim2Realを楽しみました。
良い結果を得ることができて大変喜んでいます。
Sim2Realを経て更にフィードバックするなどしてフローをグルグル回すことでモデルの精度向上に加えて、強化学習に対する理解も増しました。
MuJoCo + Gymnasium + Stable-Baselines3 という構成の強化学習については自身で考えて好きに色々できる知識がついたかなと思っております。
引き続きリアクションホイール姿勢制御モジュールの強化学習をテーマに耐性向上なども考えてもいいのですが、そろそろ飽きてきたので本命の2足歩行ロボットに行ってしまおうと思います。
足踏み動作も整ったし前後のバランス調整して歩行と思ったけど。。
強化学習ってのが気になりだしたぜ。
一旦そっち勉強してみようかな。 pic.twitter.com/hBfzsHW4Jk— HomeMadeGarbage (@H0meMadeGarbage) May 5, 2025
それではまたお会いいたしましょう。