
AIエージェント Codex で 強化学習2
起き上がりロボ
本記事にはアフィリエイト広告が含まれます。
前回はAIエージェント Codexに強化学習を実施してもらい2足歩行ロボットのバランス動作を実現しました。
Codex先生が学習の環境構築、報酬設計、学習フローすべて考えてくださり、長年憧れていた動作ができました。
Codexで強化学習
Sim2Real pic.twitter.com/PLPGPFwXDh— HomeMadeGarbage (@H0meMadeGarbage) June 9, 2026
ついに忌まわしき報酬設計から解放されたので、ここからは強化学習ありきのモノづくりにシフトしていきます。
いくでぇ!

目次
憧れ
次に実現したい動作はこれです。
これとか
Fascinating little guy from r/mondorobotics pic.twitter.com/dEaGthEJdC
— 🐧 Daniel Garcia | therobotbay.com – Robot market (@dannybuntu) March 15, 2026
これとか
We just open-sourced luwu_mjlab: an RL training environment for Luwu Dynamics quadruped robots.
Built on mjlab + MuJoCo Warp, it lets us train locomotion and get-up policies in simulation, then validate them on real robots.GitHub:https://t.co/O7jovxOqRF pic.twitter.com/HSpPhRylfu
— XGO Robot (@luwu_dynamics) June 13, 2026
転んでも起き上がるロボを実現したいです。
人工的なシーケンスではなく、上の動画のロボのように強化学習を用いれば
まるで生き物のような動作になるのではと目論んでおります。
機体デザイン
まだまたAI強化学習ビギナーの私ですのでいきなり倒立振子や犬ロボに手を出しても発散に次ぐ発散できっと成果はでないと思います。
ここでは以下のような簡単な2軸ロボで起き上がり動作を目指します。

Fusionで設計しました。アームの長さとかは感覚で決定 (俺センス ハンパないから)。
Fusionで設計したロボのSTLモデルからMuJoCoモデルを作成
MuJoCoモデル完成 pic.twitter.com/etZWVbWBS9
— HomeMadeGarbage (@H0meMadeGarbage) June 9, 2026
STLモデルと質量や慣性モーメント情報をCodex先生に共有するだけでMuJoCoモデル完成するかなと思いきや、わけわからないオリジナルロボなためか回転軸などを明確に手で指定する必要がありました (あまり時短にはならんかったわ)。
PWMマイクロサーボを2個、コントローラはIMU内蔵のATOM Matrixの使用を想定しています。
MuJoCoのサーボモデルにはposition actuatorを採用して可動範囲を±90°としました。
ゲイン等は小さめに適当に設定しました。
いったんこのロボで学習して問題があれば機体デザインやアクチュエータゲインを修正する方向で行きます。
強化学習
製作したMuJoCoモデルで倒れた状態から起き上がる動作を学習しました。
学習は Gymnasiumベースの強化学習環境を Stable-Baselines3(PPO )でCPU並列処理で実施
環境構築と報酬や学習フローはCodex先生に丸投げしました。
そして学習結果が以下の通り
Codexで強化学習
憧れの何度倒しても起上るロボ
ええ学習ポリシーが手に入りました pic.twitter.com/svKJvGhmrZ— HomeMadeGarbage (@H0meMadeGarbage) June 9, 2026
ヤバいね。ロボを倒すとアームを動かして起上ってます。
ニューラルネットワークが姿勢を判断して適切な動作で起き上がりを実現しています。
凄すぎるよね。
学習の観測ベクトルが
roll角 [rad]
pitch角 [rad]
servo1_target 下段サーボ目標角 [rad]
servo2_target 上段サーボ目標角 [rad]
行動ベクトルは
servo1_target_delta [rad]
servo2_target_delta [rad]
コチラは目標角ではなく変化量になっています。何気にコレには感心しました。
制御周期が50Hzで変化量がMax ±0.08 radで設定されているので、サーボの速度は約38 rpmと普通のPWMマイクロサーボでも問題なく出せるスピード想定となっております。
事前にPWMサーボを使用することは伝えて、アームの高速動作での振り上げではなくゆっくり確実に起き上げていただくようにお願いしました。そのため行動ベクトルにサーボの変化量が設定されたのでしょう。
流石です。
学習ポリシー(ニューラルネットワーク)の構成は以下の通り
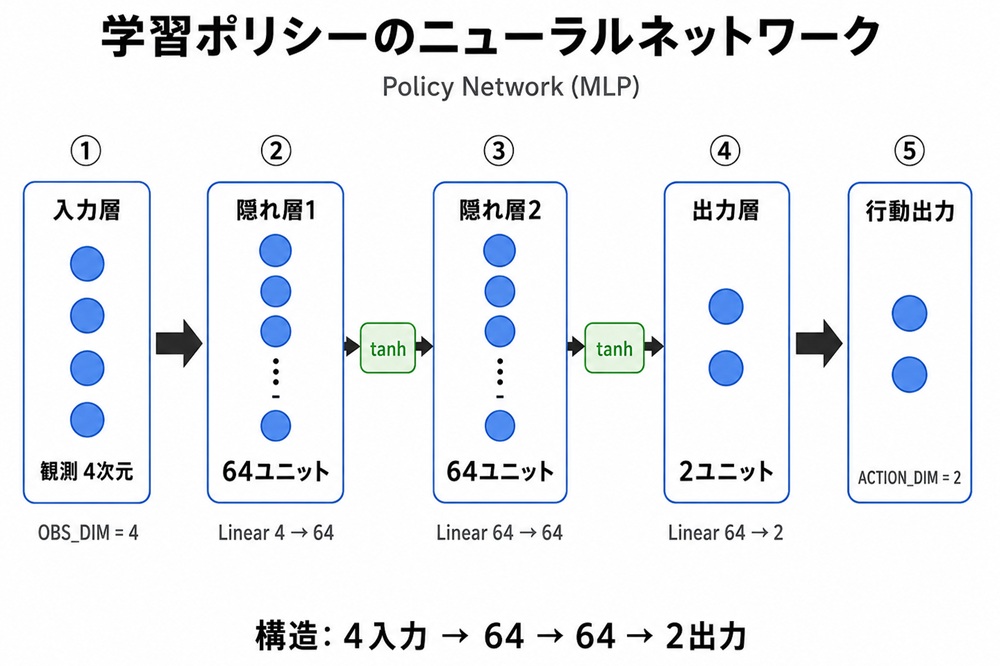
Codex先生による詳細説明
MuJoCo 上の robo1.xml に、2個のサーボ関節を制御する position actuator を追加した。
制御対象は servo1_joint と servo2_joint で、行動ベクトルは2次元のサーボ目標角変化量とした。
観測ベクトルは、実機の PWM サーボで取得できる情報に合わせて4次元にした。
roll
pitch
servo1_target
servo2_target
ここで servo1_target と servo2_target は、実際のサーボ角ではなく、直近に送った目標角である。
PWM サーボでは実角度を直接読めないため、ポリシーにはサーボ実角を見せない構成にした。
行動ベクトルは次の2次元にした。
servo1_target_delta
servo2_target_delta
ポリシーの出力は -1 から 1 の範囲とし、環境側で次のようにサーボ目標角へ反映した。
target += action * 0.08
target = clip(target, -1.55, 1.55)
つまり、1制御ステップごとに各サーボの目標角を最大 0.08 rad ずつ動かす。
これにより、実機の小型サーボでも急激に動かず、ゆっくり準静的に起き上がる動作を学習しやすくした。
MuJoCo の物理モデルでは、foot body に free joint を持たせ、ロボット全体が床上で自由に倒れたり起きたりできるようにした。
起き上がりの最終姿勢は、foot が床に接地して直立し、servo1 と servo2 がほぼ 0 deg に戻った状態とした。
成功判定では、機体が直立していること、サーボ角が 0 付近にあること、速度が小さいことを確認した。
最初に、4種類の倒れ姿勢を定義した。
roll_pos
roll_neg
pitch_pos
pitch_neg
それぞれ、左右横倒しと前後倒れを表す。
各姿勢から起き上がるためのサーボ目標角シーケンスを用意し、リファレンス動作として使った。
リファレンス動作は、複数の waypoint で構成した。
各 waypoint は servo1_target と servo2_target の目標値であり、環境側では waypoint 間を滑らかに補間してサーボを動かした。
最後の waypoint は必ず [0, 0] とし、起き上がった後にアームがピン立ち、つまりサーボ0 degへ戻るようにした。
このリファレンス動作を教師データとして、観測と行動のペアを収集した。
収集したデータは、各時刻の観測ベクトルと、その時刻に出すべき action で構成した。
action は、現在の target から次のリファレンス target へ近づくための delta とした。
action = clip((reference_target – current_target) / 0.08, -1, 1)
この教師データを使って、Stable-Baselines3 の PPO ポリシーを behavior cloning 的に事前学習した。
PPO の MlpPolicy を作成し、ポリシーが出力する action の平均値が教師 action に近づくように、平均二乗誤差で学習した。
学習後、4種類の倒れ姿勢すべてでポリシーを評価した。
評価では、reset 後にポリシーの action を逐次適用し、直立姿勢へ到達して一定時間維持できるかを確認した。
評価対象は次の4姿勢である。
roll_pos
roll_neg
pitch_pos
pitch_neg
すべての姿勢で goal_pose が True になり、success_count が 50 に到達することを確認した。
この時点のポリシーを robo1_getup_ppo.zip として保存した。
機体製作
設計したロボで問題なく起き上がり学習ができましたので、そのままの寸法で実機製作します。

サーボとATOM Matrixの接続コードはこんな感じに加工

構成
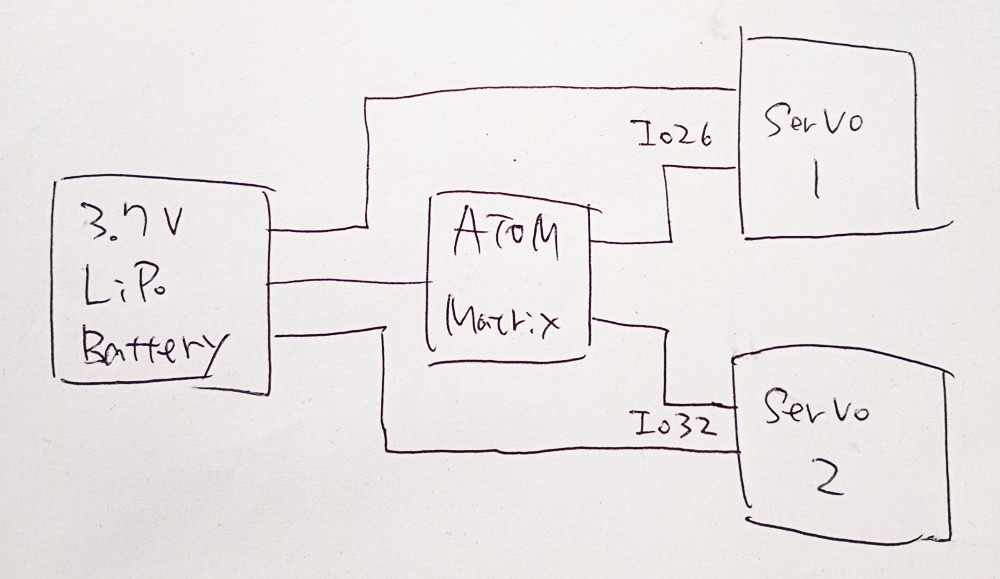
- ATOM Matrix
- サーボモータ PTK 7465 MG

- 3.7V LiPoバッテリ


Sim2Real
学習データを製作した実機に移植して動作させます。
Codexで強化学習
生き物つくってもうた。。 pic.twitter.com/uQDPUMwpV4— HomeMadeGarbage (@H0meMadeGarbage) June 10, 2026
見事に起き上がり動作が実現されました!
学習ポリシーはそのまま導入のゼロショットで動作しました。
実機ではオイラー角を使用しているため、90°以上傾いた際にジンバルロックで異常値が出ます。
そのため若干起きにくそうな動作になったりします。
しかし一生懸命起き上がろうとする動きも生き物みたいで面白いのでこのままでいいかな。
クォータニオン由来で姿勢角を算出するようにすれば解決します (次の記事参照)。
憧れの蹴り飛ばし無限起き上がりも実現できました。
フィジカルAIって、心を鬼にしないといけない時がある pic.twitter.com/AaYErg2T9a
— HomeMadeGarbage (@H0meMadeGarbage) June 10, 2026
おわりに
ここではAIエージェント Codexに起き上がりロボの強化学習を実施してもらいました。
Sim2Realで実機動作も確認ができ、憧れの蹴り飛ばし行為も実施できました。
もろもろのデータを以下にアップしましたので、ご興味がありましたら見てみてください。

今回は強化学習することを前提に機体を設計し、学習後に実機を製作しました。
当初目的のAI強化学習込みでの製作フローを確立することができました。
簡素なロボでやりたいことができたので次は4脚ロボとかで挑戦してみようかしら 🙄
ほな








Nice project, am trying to replicate. Did you need to boost the 3.7v to 5v to make it work? Thanks.
ありがとうございます。
3.7Vでいけました
リファレンスつまり、教師データを作る方法がいまいち分からなくて。。。
今ClaudeOpusといっしょに初めての強化学習をやっているのですが、成功したりしなかったりで躓いており、教師データを作り直そうと思ったらパラメータだけ書かれてあって過程が分かりません。
是非教えてください!
教師出た探索用コード search_all_getup.py を追加しました。
https://github.com/homemadegarbage/SelfRisingRobot/tree/main/RL
参考になれば幸いです。
ありがとうございます。確認しますね!
あと実は裏で教師データなしの方を先に動かしてました。一応それでも動いたのですが成功報酬を決めるが恐ろしく大変でした!!!
教師データがあったほうがやっぱいいのでしょうか。。。。
教師データなしでもできると思いますが
仰るように報酬設定で動作を設計することになるので難易度は高くなると思います。
AIは動作探索にも強いのでベースとなるリファレンス動作を探索してそれを教師データとして強化学習で精度あげるのが効率的だと感じます。