AIエージェント Codex で 強化学習
2足歩行ロボット HM-01
本記事にはアフィリエイト広告が含まれます。
最近はAIエージェント Codexをさわって色々楽しませていただいております。
今回はCodexで強化学習を楽しみましたので報告いたします。
テーマとして2足歩行ロボットのバランス動作を選択しました。
これまた生活変わるレベルで驚かされました。

目次
2足歩行ロボットの強化学習
2足歩行ロボットの強化学習については以前から取り組んでおりました。
直近ではリファレンスとして歩行動作をあらかじめ用意して、転ばずにバランスするように学習する方法を検証し歩行動作まで確認しました。
強化学習の有用性は実感していたのですが、計算量が多くなることと学習のための報酬設計がかなり難しいことがネックとなっておりました。
時間が溶けるので、ここのところ避けていた強化学習ですが、Codexの活用で楽になるのではと考えました。
以前から実現したかった、ロボットを押すと受け流すように歩きながらバランスを保つ動作を目標にします。
報酬設計がうまくいかず、ずっと実現できなかった動作です。
押した時に力を逃がす様に少し歩いてほしんだよなぁ
報酬設計がうまくいかなくて気が狂いそう
来年には報酬設計すらしなくてよくなってると思うからより狂いそう https://t.co/0tIPiEcV8H— HomeMadeGarbage (@H0meMadeGarbage) October 12, 2025
Codex で強化学習
Codex先生に学習方針を相談して、以下の順で実施することとなりました。
MuJoCo+PPOで直立を学習→足上げを訓練→外乱stepバランス回復を学習
観測ベクトルと行動ベクトルは以前の強化学習と同じ構成を指定しました。
実機の構成は変えたくないので。
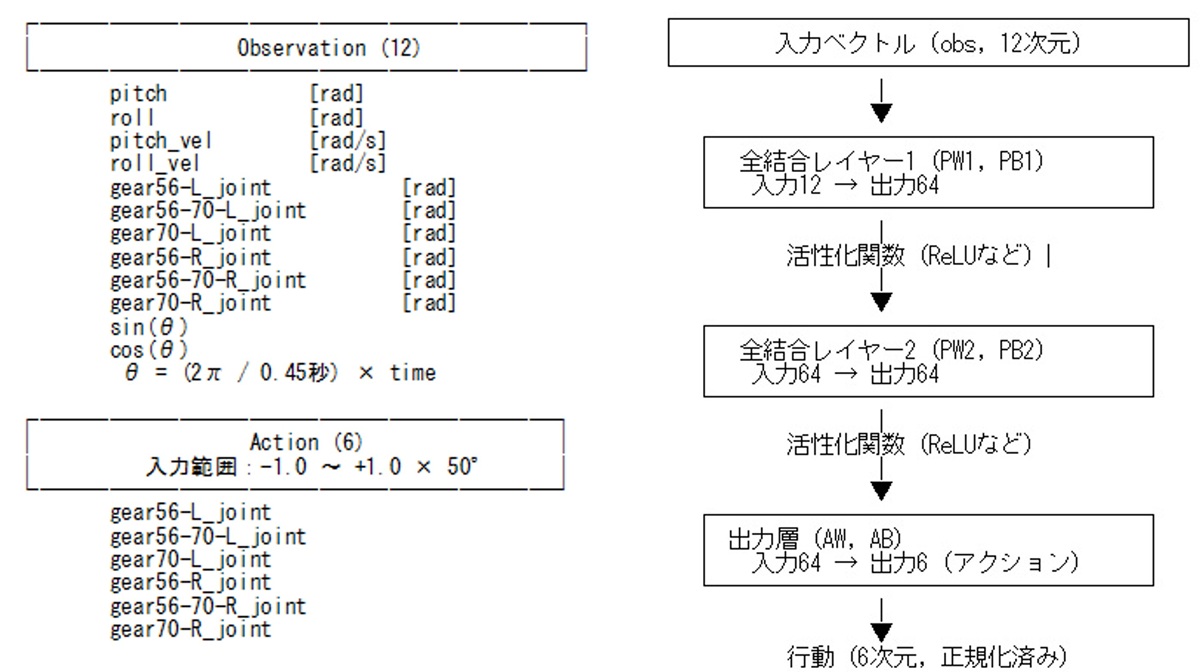
観測ベクトル (12次元)
・機体ロールピッチ角度/角速度 (4)
・各モータの角度 (6)
・時間同期用のsin, cos (2)
行動ベクトル (6次元)
・各モータの目標角度 (6)
学習は Gymnasiumベースの強化学習環境を Stable-Baselines3(PPO )でCPU並列処理で実施
直立
直立訓練はすぐに実現されました。
ロボットモデルの6個のモータ角度を0にすれば直立体制となるのでね。
しかし学習環境設計も報酬設計も自動的に生成され学習結果が得られたことに大変驚きました。
学習結果で直立できていることを確認できたので次のステップに進みました。
足上げ訓練
バランス動作のまえに足を上げての足踏みを実現する訓練が実施されました。
直立動作の学習結果を引き継いで学習開始。
ここでも全くのノータッチで学習結果を得ました↓。
Codex で 強化学習
まずは外乱なしで足踏み動作を学習で実現していただく
Sim2Realを見据えているので観測ベクトルだけ指定させていただき後はほぼノータッチこのくらいなら自身でも報酬設計して実現できるだろうけどノイローゼにはなると思う pic.twitter.com/evV91pmGnd
— HomeMadeGarbage (@H0meMadeGarbage) June 8, 2026
見事な足踏みが実現されています。
このくらいの動作ですと自分で報酬設計をしても恐らくは実現できそうですが、1週間はかかるでしょうねぇ。。
ここまでわずか数時間しかたっていませんでした。しかもほぼ何もせずボーっとしていただけです。
まじでやばい
バランス動作
足踏み学習結果を引き継いで外乱を加えてのバランス動作の学習を実施
Codex先生はいろいろ条件を探索しながら結果を出してくれました。
さすがに数時間やってた (はじめてCodexの5時間使用リミットにかかりました)。
Codexで強化学習
憧れの押したらおっとっととバランスするニューラルネットワークでけた
Codex先生に丸投げでどういう報酬で学習したのか全くのノータッチ
興奮するなぁ#codex #ReinforcementLearning pic.twitter.com/EvJ3w4rQ5p
— HomeMadeGarbage (@H0meMadeGarbage) June 8, 2026
ついに押されたら小刻みステップして転倒回避する学習ポリシーが実現されました!!
後述しますが学習のために設計された報酬は絶対自分では実現できるものではありませんでした。
Codex先生のおかげで報酬設計から解放され今後の生活に光が強く差しました。
Sim2Real
得られた学習ポリシーをATOM Matrix (ESP32)に移植して動作確認を実施しました。
Sim2Real
学習結果を実機に移植
若干動作の周期だけ遅く調整(モータのモデリング甘いんだわ)なんか神経通ってる動作になって面白い#強化学習 https://t.co/E8GO2BiXmf pic.twitter.com/AaNV9tKEib
— HomeMadeGarbage (@H0meMadeGarbage) June 9, 2026
押したら歩く動作が実現されております。
移植の際に足のモーション周期を少し遅くなるように修正しました。
足動作指令が早すぎて追従できなかったため。
この辺はモータのモデリングに甘さがあるのだと思います。
長年出来ずに憧れていた動作が一晩で実現されました。
おわりに
ここではAIエージェント Codexに強化学習を実施してもらいました。
やりたいことを伝えるだけで学習の方針や環境設計まですべてCodex先生がやってくれました。
自分の中でかなり大きな障壁となっていた報酬設計から解放され、今は希望に満ち溢れる思いでいます。
今後はモノづくりの際に初手で強化学習含みで考えられるので、楽しみが増えそうです。
今回はCPUによる学習でしたがIsaac SimなどでGPUによる環境ごと大量に並列処理ができれば更に更に可能性は増しそうです。
思いつきさえすればAI活用との組み合わせによってなんでもできてしまうのでは。。
いやぁワクワクしますね。
学習の流れ
今回Codex先生が実施した学習のフローをまとめていただきました。
長いですがもし興味があれば
今回の stand_model_step_nn.zip は、倒れそうになったときに左右交互に足を出して復帰するためのNNポリシーです。
学習は大きく2段階で行いました。
1. 教師あり事前学習
2. PPOによる強化学習
最初からPPOだけで学習させるのではなく、まず「倒れた方向に応じて、左右交互に足を出す」動作を教師データで覚えさせ、その後MuJoCo環境内でPPOにより調整しました。
学習モード
学習には train_stand.py の –mode step_nn を使います。
python train_stand.py –mode step_nn
step_nn モードでは以下の設定になります。
“step_nn”: {
“disturbance”: True,
“step_recovery”: True,
“step_practice”: False,
“neural_step_control”: True,
“model_path”: “stand_model_step_nn”,
“checkpoint_dir”: “checkpoints_step_nn”,
“resume”: “stand_model_practice”,
}
ポイントは neural_step_control=True です。
通常の step モードでは、環境側のルールで復帰ステップの開始タイミングを管理します。一方 step_nn では、NNポリシーが観測ベクトルと歩行phaseを使って足出し動作を行います。
踏み出しトリガー
直立中にNNが微小な足出しをして揺れるのを防ぐため、外側に明確な踏み出しトリガーを入れています。
現在の条件は以下です。
開始条件: abs(pitch) > 6.5 deg
終了条件: abs(pitch) < 3.5 deg
最低継続時間: 0.55 sec
実装イメージは以下です。
if nn_step_active:
nn_step_active = (
nn_step_min_steps > 0
or abs(pitch) > release_angle
)
else:
nn_step_active = abs(pitch) > trigger_angle
if nn_step_active:
gait_phase0 = -omega * time
nn_step_min_steps = int(0.55 / dt)
if not nn_step_active:
action = 0
トリガー前は action = 0 に強制します。これにより、直立中はNN出力に微小な揺れがあってもサーボ指令には反映されません。
一度トリガーしたら最低 0.55秒 は歩行phaseを維持します。これにより、倒れそうな瞬間に片足だけ出してすぐ止まるのではなく、左右交互の「おっとっと」動作が出やすくなります。
観測ベクトル
NNへの観測は12次元です。
obs = [
pitch,
roll,
pitch_vel,
roll_vel,
joint_angle_0,
joint_angle_1,
joint_angle_2,
joint_angle_3,
joint_angle_4,
joint_angle_5,
sin(phase),
cos(phase),
]
左右交互の足出しには sin(phase), cos(phase) を使います。
feed-forward NN単体には内部記憶がないため、「今は左足のフェーズか、右足のフェーズか」を観測として渡す必要があります。
教師あり事前学習
まず pretrain_step_nn_policy.py で教師あり学習を行いました。
実行コマンドです。
python pretrain_step_nn_policy.py \
–source stand_model_practice \
–output stand_model_step_nn
stand_model_practice.zip を元にして、足出し用の初期ポリシー stand_model_step_nn.zip を作ります。
教師データでは、pitch角から倒れ方向を判定します。
balance_signal = pitch
if abs(balance_signal) < trigger_angle:
action = 0
else:
direction = -sign(balance_signal)
足出し動作はphaseで分けています。
if local_phase < 0.12:
leg_action = [-0.75, 0.75] # 踏み込み準備
elif local_phase < 0.36:
leg_action = [0.95, -0.95] # 足上げ
elif local_phase < 0.74:
leg_action = [direction * gain, direction * gain] # 倒れ方向に応じて足を出す
else:
leg_action = [0, 0] # 戻す
左右どちらの脚を動かすかはphaseから決めます。
drill_idx = int(phase * 4.0)
swing_idx = 0 if drill_idx in (0, 2) else 1
これにより、左、右、左、右のように交互に足を出す基礎動作をNNに覚えさせます。
PPOによる強化学習
教師あり事前学習後、PPOで仕上げます。
python train_stand.py –mode step_nn –timesteps 200000 –eval-episodes 5
学習時は stand_model_step_nn.zip が存在すれば、そこから再開します。
if resume is None and args.mode in (“practice”, “step_nn”) and os.path.exists(f”{model_path}.zip”):
resume = model_path
PPOの主な設定は以下です。
PPO(
“MlpPolicy”,
env,
policy_kwargs={
“net_arch”: [64, 64],
“log_std_init”: -2.0,
},
learning_rate=3e-4,
n_steps=512,
batch_size=512,
gamma=0.99,
gae_lambda=0.95,
clip_range=0.2,
normalize_advantage=True,
device=”cpu”,
)
step_nn 専用報酬
step_nn 用の報酬では、トリガー前とトリガー後で役割を分けています。
トリガー前
トリガー前は静止直立を重視します。
step_reward += 8.0
step_reward -= 16.0 * sum(action^2)
step_reward -= foot_position_error
step_reward -= joint_pose_error
目的は以下です。
– actionを出さない
– 足位置を動かさない
– 関節を直立姿勢に保つ
– 直立中の微小な揺れを抑える
トリガー後
トリガー後は倒れ方向に足を出すように報酬を与えます。
target_step = direction * clip(abs(pitch) / 28deg, 0.012, 0.045)
desired_y = target_step if 0.18 < local_phase < 0.72 else 0.0
desired_z = 0.035 if 0.10 < local_phase < 0.48 else 0.0
足出し報酬です。
step_reward += 70.0 * clip(direction * swing_y, 0.0, 0.055)
step_reward += 70.0 * clip(swing_z, 0.0, 0.040)
step_reward -= 1200.0 * (swing_y – desired_y)^2
step_reward -= 900.0 * (swing_z – desired_z)^2
step_reward -= 60.0 * (stance_y^2 + stance_z^2)
意味は以下です。
– 倒れ方向に足を出す
– 足を少し上げる
– 目標位置に近づける
– 支持脚は暴れさせない
全体報酬
最終的な報酬は、直立維持報酬と足出し報酬を合成しています。
upright_reward = exp(-10*pitch^2 – 22*roll^2)
still_reward = exp(-0.08*pitch_vel^2 – 0.16*roll_vel^2)
reward = (
3.0 * upright_reward
+ 0.8 * still_reward
+ 0.5
+ step_reward
– roll_penalty
– leg_roll_penalty
– foot_position_penalty
– symmetry_penalty
– joint_angle_penalty
– joint_velocity_penalty
– action_penalty
– hip_velocity_penalty
– hip_position_penalty
)
基本は直立維持です。その上で、倒れそうなときだけ step_reward によって足出しを誘導します。
評価
学習後の評価コマンドです。
python evaluate_stand.py –mode step_nn –episodes 10
今回の採用モデルでは以下の結果でした。
success=1.00
duration=10.00s
foot_step=0.019m
foot_lift=0.036m
追加で強めの短い押しを入れたテストでは、左右交互の足出しが確認できました。
force=4.0N, duration=0.12s -> survived=True, switches=2
force=5.0N, duration=0.12s -> survived=True, switches=3
一方で、長時間押され続けるケースはまだ弱いです。
force=3.5N, duration=0.70s -> failed
このため、今後改善するなら slow push 用の報酬やトリガー継続条件を追加するのが有効です。
Sim2Simでの注意点
Sim2Simや実機でNNを使う場合、NN出力をそのままサーボに入れるのではなく、学習時と同じ外側ゲートを入れる必要があります。
if abs(pitch) > 6.5deg:
step_active = True
if step_active:
最低0.55秒はphaseを回す
if abs(pitch) < 3.5deg and 最低時間経過:
step_active = False
else:
action = 0
このゲートを入れないと、直立中でもNNの微小出力がサーボに入り、少し揺れることがあります。
まとめ
stand_model_step_nn.zip は以下の手順で作りました。
python pretrain_step_nn_policy.py \
–source stand_model_practice \
–output stand_model_step_nn
python train_stand.py \
–mode step_nn \
–timesteps 200000 \
–eval-episodes 5
ポイントは以下です。
– まず教師あり学習で左右交互ステップを覚えさせる
– PPOでMuJoCo上の復帰動作に合わせて調整する
– 直立時はactionをゼロにする
– pitch角で踏み出しを開始する
– 一度踏み出したら最低時間だけ歩行phaseを維持する
– phaseを観測に入れて、feed-forward NNでも左右交互動作を作れるようにする
この構成により、直立時は静止し、倒れそうなときだけ左右交互に足を出して復帰する step_nn ポリシーを作ることができました。